FilmGirl 胶片风 Film Grain LoHA & LoRA
файл на civitaiстраница на civitai这是用于生成胶片风格AI写真照片的LoHA & LoRA模型。与majicMIX realistic、MoonMIX或Chilloumix搭配使用,可以生成逼真的胶片风格照片。同时推荐搭配TEXTUAL INVERSION模型:bad_pictures、negative_hand Negative Embedding。这两个Negative Embedding模型不会显著影响到胶片的质感。
This is LoHA & LoRA models for generating film style AI portrait photos. when used with majicMIX realistic、 MoonMIX or Chilloumix, it can generate realistic film style photos. At the same time, it is recommended to use the TEXTUAL INVERSION model: bad_pictures, negative_hand Negative Embedding. These two Negative Embedding models will not significantly affect the film texture.
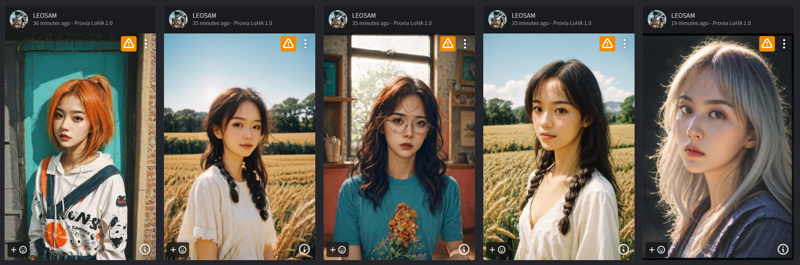
由于新版本的Provia模型太过真实,我上传的好多效果图被系统判为疑似真实照片给夹了。。我只能先AI生成些离谱内容的预览图,不然过不了审。。。
Because the effects of the new Provia model are too realistic, many of the effect pictures I uploaded were judged by the system as suspected real photos and were rejected. I can only first generate some absurd preview pictures...
2023.5.19 Introducing "the Provia Version: FilmGX2 LoHA model "
Provia版本不同于之前0.1到4.0版本LoRA模型,Provia是全新的胶片模拟LoHA模型,使用60张优选后的胶片照作为训练集,以及505张胶片照作为正则化图像集训练而来。
The Provia version is different from the previous Lora models from 0.1 to 4.0. Provia is a brand new film simulation Loha model, trained with 60 selected film photos as the training set and 505 film photos as the regularization image set.
使用Loha模型的一种方法:
请安装以下插件,https://github.com/KohakuBlueleaf/a1111-sd-webui-locon,然后调用方法与Lora类似,需要将模型放入...\models\Lora文件夹中,随后使用<lora:FilmProvia2:XXX>指令调用。
另一种使用Loha模型的方法: → https://github.com/KohakuBlueleaf/a1111-sd-webui-lycoris
How to use the Loha model:
Please install the following plugins, https://github.com/KohakuBlueleaf/a1111-sd-webui-locon, then use the same method as Lora. You need to place the model in the \models\Lora folder, and then call it with the <lora:FilmProvia2:XXX> command.
Another way to use the Loha model → https://github.com/KohakuBlueleaf/a1111-sd-webui-lycoris
Provia版本的胶片质感要明显强于1.0到4.0版本,面部正确率要明显强于0.1和0.2版本。如果你非常在意胶片真实质感,那这个版本是整个胶片系列模型中最推荐使用的版本。但请注意,因为这个版本没有融合其他模型进行面部优化,因此面部崩坏的概率会比v4高一些。
The film texture of the Provia version is significantly stronger than versions 1.0 to 4.0, and the face accuracy rate is significantly stronger than versions 0.1 and 0.2. If you are very concerned about the real film texture, this version is the most recommended in the entire film series model. But please note that because this version does not integrate other models for facial optimization, the probability of facial collapse will be higher than v4.
请注意:
Provia版本不在需要Trigger Words。
我常用的CFG范围是6~7,Lora权重通常在0.6~0.8。
Clip skip设为1或2时,生成的效果会有所不同,大家可以多尝试看自己喜欢哪种风格。
本LoHA模型的训练集主要为亚洲胶片人像照片,生成欧美人像的效果会受影响。
Please note:
The Provia version no longer requires Trigger Words.
My commonly used CFG range is 6 to 7, and the Lora weight is usually 0.6 to 0.8.
When the Clip skip is set to 1 or 2, the generated effects will be different. You can try more to see which style you like.
The training set of this LoHA model is mainly Asian film portrait photos, and the effect of generating European and American portraits will be affected.

































