I'm in the middle
файл на civitaiстраница на civitaiI like math
Токены:
SHA256: E4A7E57CF40E1A1E785D16B6D8EB1B42B22DAB1E2CB716D77EEACF2510BA4535mathematical equations
I like math
mathematical equationsSeraph_Mix is meant to be a beautiful and colorful/bright hentai mix.
When I was creating this, I really liked 2 models in specific, but wondered what happened if i mixed them both, and honestly, I was not disappointed. It is really colorful, and amazing and doesn't even require much describing for it to be amazing.
-
Checkpoints involved in Seraph_mixV1 :
Checkpoints involved in Seraph_mixV2 :
Checkpoints involved in Seraph_mixV3 :
Version 4 is my secret!
baked in :
-
It is recomended to use (512x768), (Euler A), and a (CFG Scale of 7)
(768x768) images are still good and possible :
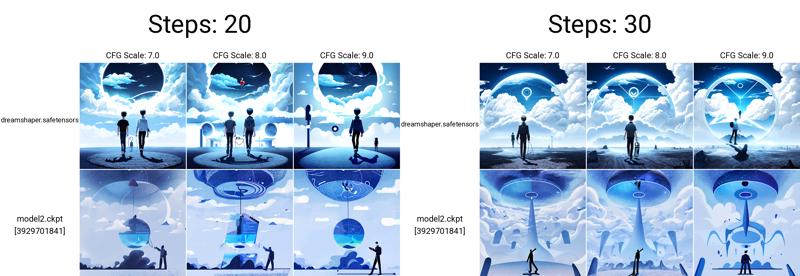
Example Generation
Positive prompt: 1girl[mature woman], [extremely detailed:1], [medium-small boobs:0.2], [blush, black hair, medium-long hair], bedroom, [sexy black panties, sexy black bra], nice hands, perfect hands], <lora:GoodHands-beta2:1>
Negative prompt: (worst quality, low quality:1.4), EasyNegative, bad anatomy, bad hands, cropped, missing fingers, missing toes, too many toes, too many fingers, missing arms, long neck, Humpbacked, deformed, disfigured, poorly drawn face, distorted face, mutation, mutated, extra limb, ugly, poorly drawn hands, missing limb, floating limbs, disconnected limbs, malformed hands, out of focus, long body, monochrome, symbol, text, logo, door frame, window frame, mirror frame, flat chest,
Steps: 30, Sampler: Euler a, CFG scale: 7, Seed: 2490512948, Size: 768x768,
-
LORA's from "ddp12" are pretty cool.
I also recommend using this LORA : "BetterHands" - By Envy
-
Thank you to the creators of both Yesmix, and AOM3, without them i would not have been able to create such a beautiful checkpoint merge.
Thank you the creators and mods of Yodayo, AI generation website, as without them i would not be here today making good images and checkpoint merges.
-
Special thanks to you, for downloading! : D

This is a global repository of the Dreambooth Checkpoints.
Some people asked me to upload the source Dreambooths from which I make the LyCORIS.
To not spam the site/profile with multiple models I decided to do it the same way I intended to handle the Game characters -> a single page where each model is just a separate version.
NOTE: This is for those who prefer to get the maximum quality! If you are fine with the quality of the LyCORIS, you may want to skip it (however, I imagine I might upload some models here before I convert them into LyCORIS for time reasons).
However, If you prefer LyCORIS - you need not download anything from here because I eventually will upload all those models in the LyCORIS version :)
sks person
A merger of Darkgemini and Alfahentai, to make a model which excels in generating anime images using natural language.

Get in 🤗Hugging Face: Hugging Face-Ojimi/anime-kawai-diffusion
Kawai is a special AI art model that focuses on depicting cute and petite girls, which is in contrast to most existing models. Kawai has everything you need, including 'it' - if you know what I mean. So, I wish you all the best.
Kawai v4-charm LTS version (snapshot 16-04-2023). Read more about it in the "About this version" section.
This version has been created with significant contributions from many individuals and sleepless nights from me and my friend (Amigi). Thank you for supporting us all this time.
Facts: Based on our experiments, the "DPM adaptive" and "DPM++ 2M Karras" sampling method performs best on Kawai Diffusion, although it comes with a considerable trade-off in terms of computational requirements.
⚠️ Usage warning:
The output images may not be suitable for all ages, please use with additional safety measures. (violence, sexual)
Some parts of the model may not be suitable for you. Please use it with caution.
For 🧨Diffusers:
from diffusers import DiffusionPipeline
pipe = DiffusionPipeline.from_pretrained("Ojimi/anime-kawai-diffusion")
pipe = pipe.to("cuda")
prompt = "1girl, cat ears, blush, nose blush, white hair, red eyes, masterpiece, best quality, small breasts"
image = pipe(prompt, negative_prompt="lowres, bad anatomy").images[0]Try it in Google Colab!
Chat GPT with Kawai Diffusion (or any model if you like.)
Read the following instructions, and if you understand, say "I understand": Command prompt structure: includes descriptions of shape, perspective, posture, and landscape,... Keywords are written briefly in the form of tags. For example "1girl, blonde hair, sitting, dress, red eyes, small breasts, star, night sky, moon"The `masterpiece` and `best quality` tags are not necessary, as it sometimes leads to contradictory results, but if it is distorted or discolored, add them now.
The CGF scale should be 7.5 and the step counts 28 for the best quality and best performance.
Use a sample photo for your idea. Interrogate DeepBooru and change the prompts to suit what you want.
You should use it as a supportive tool for creating works of art, and not rely on it completely.
Normal: Clip skip = 2.
As it is a version made only by myself and my small associates, the model will not be perfect and may differ from what people expect. Any contributions from everyone will be respected.
Want to support me? Thank you, please help me make it better. ❤️
Runwayml: Base model.
CompVis: VAE Trainer.
stabilityai: stabilityai/sd-vae-ft-mse-original · Hugging Face
d8ahazard: Dreambooth.
Automatic1111: Web UI.
Mikubill: Where my ideas started.
Chat-GPT: Help me do crazy things I never thought I would.
Novel AI, Anything Model, Abyss Orange Model, CentusMix Model, Grapefruit Model: Dataset images. An AI made me thousands of pictures without worrying about copyright or dispute.
Danbooru: Help me write the correct tag.
My friend and others: Get quality images.
And You 🫵❤️
This license allows anyone to copy, and modify the model, but please follow the terms of the CreativeML Open RAIL-M. You can learn more about the CreativeML Open RAIL-M here.
If any part of the model does not comply with the terms of the CreativeML Open RAIL-M, the copyright and other rights of the model will still be valid.
All AI-generated images are yours, you can do whatever you want, but please obey the laws of your country. We will not be responsible for any problems you cause.
We allow you to merge with another model, but if you share that merge model, don't forget to add me to the credits.
Don't forget me.
I have a hero, but I can't say his name and we've never met. But he was the one who laid the foundation for Kawai Diffusion. Although the model is not very popular, I love that hero very much. Thank you for your interest in my model. Thank you very much!
Buy me ko-fi: https://ko-fi.com/ojimi (≧∇≦)ノ

i'm trying to create a clean western cartoon style without japanese anime influence, hope u like it

A fking StableDiffusion model
Trained on multiple scifi/fantasy concepts for a general, but limited sci-fi model. It has been trained on armour concepts, futuristic backgrounds, androids and robots, as well as some fantasy stuff, like werecreatures.
Additional Notes
Be sure to grab to YAML file too, and place it in the same directory as the downloaded model. It must be named exactly the same, except for the extension, i.e, fking_scifi.safetensorsand fking_scifi.yaml.
Primary trigger word is fking_scifi, but you can also use this to help (a bit outdated, but should still give you ideas) guide your prompting.
This model was trained on images around 896x896 pixels, meaning lower resolution images, <= 768 may not give the best results. Please use at least 768x768 before complaining that the model does not work for you. I would also recommend a CFG around 4-7 or you will experience image burn. Another tip, works best at lower steps on most sampling methods, or you will also feel the burn :fire:
Low-awaited update for fking_scifi model that, while I am not completely happy with, works well enough for me after many a training session and frustrations. This model responds to prompts different, and your previous prompts may not work like expected.
One other change is that the trigger word was changed from fking_scifi_v2 to fking_scifi without the version number. This will help future updates' ability to be merged together, although the v2 adds little weight to the overall image generation.
A v4 is already in the works...but no news on that front yet.
After testing and much debate, I have decided not to release a 1.x model. Yea I know, I'm sorry, but I am not satisfied with the results, and I do not want to share something that does not meet my standards and expectations. Long-live StableDiffusion 2.1
If you would like to contribute, either concept images, or help with the laborious process of captioning images, message me on Discord, raekor.#0768.
I'd prefer not to have merges or extractions of this model redistributed, but I am not going to report you, and I am not going to bitch about it, just make them of a higher quality.
Please remember to like or rate model. Happy prompting!
fking_scifi
Stablegram
my fanslora : fanslora.com/miaou
US/European instagram woman style
Warning: Add "nude, naked" to the negative prompt if want to avoid NSFW.
Prompting: Simple prompts are better. Large amounts of quality tags and negative prompts can have negative effects.
(Chilloutmix base) Trained with +70 000 pictures on EveryDream2
Currently working on a new version with better accuracy and consistency. By the way, have fun and don't hesitate to share your images !

This is a mix that uses a mix of furry/realistic models.
Version 6 released! Best Version Yet!!
You can see some more examples and prompts used at the model discord:
https://discord.gg/furrydiffusion
https://discord.com/channels/1019133813105905664/1059172718228025445

The next installment in my Based mixes, Based66 aims to have better LORA compatibility while maintaining the more sharper lines/softer color Anime appearance I wanted with the future installment of my models. This model was mostly made with the desire to circumvent the troubles Based65 had with LORA compatibility due to too many finetuned models which I was unaware of in the mix, so in Based66 the only finetuned model I made sure to use in the mix was HLL4, the 4th installment of the Vtuber finetuned model which I was using the 3rd version in Based64 and Based65. The 4th version of the Vtuber finetune is here like always. (B66 was also made to get into the current rise of mixes being posted online, despite B64 and B65 being uploaded to my Civitai page not too long ago those models were made way long before so B66 is the actual "new player" I decided to introduce into the current meta for more recent model mixes)
Based66 was made with a bigger focus on MBW and presets, I made sure to focus on specific seeds and the x/y grid option provided by the Supermerger to ensure specific issues were solved and avoided with earlier iterations of the model which were lost to the void (aside from the official first version of the model that I uploaded to huggingface, the only issue with that model was anatomy and some weird lighting issues but it was fixed with version 2) however those fixes lead to some good and some bad of the model which I will try fixing in the future for version 3, which currently they aren't as big of an issue like the issues with version 1 but I'll explain the good quirks and bad quirks about this model
I was testing the max steps I'm fine with 40 with CFG scale 10 with some example outputs and it works fine but you can just keep to the trusty 7 CFG scale and 20-25 steps I usually use but otherwise the most important thing to know about this model is that it's not VAE baked, so there's no VAE in this model because I prefer all models make me pick my own VAE in the stable diffusion settings so use kl-f8-anime2 by Hakurei, it looks a lot nicer in B66 avoided that super orange tint that I didn't like with B64, otherwise that's all you have to know about using this model, it works like any other Anime mix so just use it as you please, but now we get into the specific issues I saw with V2 I saw with some earlier testers
V2 needs stronger weights (1.x) with specific prompts to have the model listen to it
V2 is too faithful to LORAs leading to the need for stronger weights with specific prompts to have the model output it correctly
these are all issues I will fix in V3 however V2 being too faithful to LORAs is something I desired but at a cost, B65 had trouble with LORAs so my goal with B66 was to have it listen/understand LORAs for outputs a lot more better which it did however this issue is not as huge as the issues I saw testers have with V1, so I'm fine with this issue for now until I put effort into seeing what can fix that for version 3.
I'll see if I can upload V3 here as well, not sure if it will be the pruned version given that Civitai hates it when you try to upload models of the same sizes and almost all pruned models with the model toolkit extension makes all pruned models I have made so far the same size it's why I had to upload pruned and unpruned versions of models here to avoid that error. Of course please ensure that with whatever reply you have here that you can input regarding this model for specific fixes like the need for stronger weight prompts, I'll be sure to look into it.
Pretty sure a lot of model mixers have wrote that they would love it if you support them in anyway to links that they provide given that model mixing does take a long time (not as long thanks to supermerger but still does take a lot of time out of the day to get the right outputs) and you can do that for me, I would just be happy if you support me by looking at my Pixiv or Twitter for any outputs I make with my mixes and LORAs I train (which I will be going back to since I need to get back into the LORA meta) but if you wish to support me financially which would help me out in a lot of ways please do, I have the basic sites that most people use for donations like Ko-Fi and whatever but I also have services available for anyone that has stuff they want me to do work on, you can see all of them on my Linktree otherwise I'd only feel fine with the Patreon and Fanbox fincial support once I actually put more effort into the "exclusives" I mentioned for each site, I'll do my best with all of that but most of all just have a great time with B66 and ensure you push out any critical info of things I need to focus on fixing with V3, that's the biggest support you can do for me! Until then, I'll go back to LORA baking and focus my efforts on there until I have time to pour into making version 3 of this model that fixes the need for stronger weights on prompts.

Add a ❤️ to receive future updates.
The model has been carefully optimized for stability and reliability, and its checkpoint is regularly updated to ensure that it incorporates the latest advances in deep learning research. This means that you can trust the model to produce accurate results time and time again, making it an ideal tool for artists, animators, and anime enthusiasts alike.
So if you're looking for a powerful and dependable anime model to help you create stunning art and animations, look no further than the "Anime Model OtakuReliableEnable (AMORE)" anime model.

As always, the example images I've posted have NO postwork done to them beyond the facial fix (in some cases) and upscaling. The point is to show how well it works out of the box - if you take the time and create really good prompts and use good negative prompts (an example is at the end of this post) you can get even better results.
Normally, I wouldn't put out a new version so quickly, but I wasn't really happy with the faces on v3.4 - they would often look flat and washed out compared to the depth of the rest of the image. I also tweaked the color levels a bit to make things more colorful - though I may have gone a bit overboard. We'll play for a few days and see.
This update attempts to fix that a bit, nothing else, really. Just a bit of rebalancing.
Merged in several western art styles (American Comic and Jim Lee Style) along with a smidge of the Mistoon Emerald checkpoint to enhance the outlines without changing the styling all that much.
Keywords "Masterpiece" and "Jim Lee" will enhance (or back down if negative levels are used) the American and Jim Lee styles respectively.
All previous triggers and keywords will still work, too. (See older version notes and trigger lists for details).
As was mentioned very early on here - I'm not looking so much for characters to look real or even necessarily look exactly like the actor or actress whose name we put in the prompt. I want something that might be close, but that is consistent in composition, style, and overall appearance. Ideally, this model should be set up so that a person can make multiple images of the same person to be used for games or story telling purposes.
Updated to Babes 2.0 (the original had v1.1).
Because of the nature of that update, this tends to push the style much further back toward realism and away from the art style. I wasn't happy at first, but then realized that simply adding "digital art" and/or "cartoon" to the prompt pushed us right back to close to the style I am going for. To get more of the outline style, you can also add "warlockandboobs"
This also responds to the Hyperfusion triggers (see version 3.2 notes) as well as all the custom art styles from Babes. (Plus many many more - but the Babes trained styles are ones likely not to be found in many other models).
Important Note: I'm not entirely happy with this result - in many areas I feel it's a great step forward, but in others... well... not so much. Faces tend to have less detail on wider shots and scenes with a lot of things going on (i.e. not simple portraiture) take a lot more heavy prompting. Now, most folks are used to dealing with heavy prompting, so I'm putting this up as a beta for some feedback - but the real point of this was to be able to use fairly simple prompts to get results that satisfy your desire when you came up with the prompt. So... anyway... this needs some work. Eventually I'll either end up rolling back and remixing or finding a way forward that brings us more back on track.
Your thoughts and feedback are appreciated.
This update doesn't change the styles very much (though it's enough that you can't replicate older renders on the new version). It mainly incorporates things from Hyperfusion and Bigger Breasts. Hyperfusion is great, but it tends to sluttify the outfits, even at very low levels. By mixing in Bigger Breasts (which tries not to change up the clothing too much) and finding the right balance, it works pretty well.
A bonus is that it also lets you accomplish making breasts smaller - something very difficult to do on most models without bringing in a lot of extra help. With this "flat_chest:1.4" (or thereabouts) will do a nice job of shrinking things down in most cases. You can also use all the triggers from hyperfusion to make the breasts, butt, and belly do all sorts of things - and putting in weights there brings varied results too.
NOTE: At low levels, most of those calls don't go crazy by sexing everyone up. The higher your weights, the more likely that is to happen, so you may need to declare SFWs and even call a specific outfit in some cases. (I had to do that in the big bust sample image).
MILFY BONUS: While this isn't so much of an update as it is a little trick I learned, it is pretty cool and works well, so I thought I'd pass it along. So many models make it hard to control the age of folks - no matter what you do, the subject ends up looking under 20 (and sometimes even younger). To age folks up, use "caricature" in your prompt. The higher the weight, the older, the lower, the less aging affect it has. When adding this to your prompt, though - it will tend to push the image toward headshots - so if you're looking for something else, you'll need to call your shot and angle.
This really jumped up to the next level with a few extra tweaks to the LoRa styles plus Merging in Galena. The example images are all done with NO negative prompt and just a handful of words in the prompt - usually just a name and a quick description of what they are doing.
This also takes LoRa's and TIs a lot better than the original. For version 1 I needed to back down the weights quite considerably, for this version leaving them at the default 1.0 (or the values recommended by the creator) tended to work really well.
You can get some cool looks and variations when combining TI and LoRa triggers with the names of known celebrities, too.
This version tends to go a bit more Porny/NSFW than the original, but a lot of that is keyed into the source of the training. Celebrities who tend to not do the sexy stuff aren't as likely to default to sexy stuff - while a porn star or nude model are more likely to default to nudity and sex. Call your shots and it works out well either way, though.
Upscale is always a good thing (though in these, I just did latent) while Face Restoration is often better to leave off (but not always).
Body types tend to always be similar - but you can call them using various bodyweight/style prompts.
I wanted a model or workflow process that allowed me to quickly and easily churn out art for games and/or photo stories. I didn't want long complicated prompts to create a certain art style, but I also didn't want to be forced to use LoRa's and TI's for every character. Unfortunately, most of the models where I loved the art styles didn't do so well of loading characters (celebrities for mixing, fictional characters, etc.) and the ones that knew tons of famous characters and people tended not take to the art styles I was going for (at least not without complex prompts).
There are some great Anime style art prompts that did a nice job, but I didn't really want Anime faces (big eyes, heart shaped head with pointy chin, etc.). A wanted more of a western style, with a hint of caricature in the faces, and a consistent look from a basic <character> is wearing <outfit> at <location> type prompt.
Unfortunately, since I didn't really expect this to work, I didn't start taking notes on what all went into this until I was fairly well along. It started with a Mega Model (either SD's AIO or Clarity - I forget) and then I merged Rev Animated and Babes into that.
To my surprise, it knew LOTS of characters and celebrities (even some obscure ones that I was surprised about) and it spit out a pretty consistent style - even though it was still a bit more realistic than I wanted. It took LoRa's and style tokens well, though... so I moved to the next phase.
First I added several LoRa styles that I liked the looks of and tweaked the weights on each. They were styles that needed no triggers - so hopefully once I merged them in, then my default prompt would spit out that style every time. (Fingers crossed). I set the values so they showed up, but were low enough that the style didn't affect the clothes or other compositional elements much (if at all). The styles and the weights I ended up at are as follows: <LuisapNijijourneyLORAV2_v2:0.7>,<bootyFarmStyleLora_v10Dim128:0.4>, <lora:hungryClickerStyle_v20:0.6>
To my shock and amazement - it worked spectacularly. It wasn't quite the style I wanted, but adding simply: (bold lines:1.1), (high color), ((smooth skin)), (Masterpiece Digital Artwork:1.3), to the start of the prompt got me there. I can handle a 4 token seed prompt.
Some notes on the model:
It "mostly" defaults to SFW out of the box. i.e. If you just type in a person's name or character description with no clothes - it'll tend to put them in clothes - or at least a swimsuit. That said... with proper prompting, does nudes and porny stuff just fine, too.
I didn't care so much about making sure resulting characters look "exactly" like the person you're calling out so much as wanting to make sure that if I called out that name/person again - they'd be consistent in the way they look from image to image. So, in other words, it's not so much about "accuracy" as it is about "consistency" - and that seems to come through. (This works well for my needs to create stories and whatnot)
Depending upon the distance from camera (i.e. Closeup head shots vs. full body shots) the weight of the "bold lines" in (many of) my example prompts can be tweaked. The further back, the lower that should go and the closer in, the higher it can go.
This model (probably due to one of the LoRa styles I added) tends to want to add tattoos - even for those characters who don't have them. Adding that to the negative prompt can help (see below). Don't forget to remove those if you actually want the tattoos there.
I've added some comments to several of the example images - especially the ones without generation data.
For the sample images I used the Anything VAE (though it works fine with both the default and Anime VAEs that I tried with it). No textual inversions or LoRa usage in them - it's all coming from the checkpoint. Base images at 384x512, Euler a at 20 steps, clip skip 2, face restoration, and scale fix (2x size using latent bicubic/antialiased). The first few examples are pure raw with just a character name and/or character name + general outfit description.
Those first few examples have no negative prompt, either (just to show how well it generally behaves without them). A good neg prompt helps with various things like extra fingers/bad hands, various defects and so on. The one I use most often is: (snagged from a sample image somewhere at some point)
canvas frame, 3d, ((disfigured)), ((bad art)), ((deformed)),((extra limbs)),((b&w)), blurry, (((duplicate))), ((morbid)), ((mutilated)), [out of frame], extra fingers, mutated hands, ((poorly drawn hands)), ((poorly drawn face)), (((mutation))), (((deformed))), ((ugly)), blurry, ((bad anatomy)), (((bad proportions))), ((extra limbs)), cloned face, (((disfigured))), out of frame, ugly, extra limbs, (bad anatomy), gross proportions, (malformed limbs), ((missing arms)), ((missing legs)), (((extra arms))), (((extra legs))), mutated hands, (fused fingers), (too many fingers), (((long neck))), ugly, tiling, poorly drawn hands, poorly drawn feet, poorly drawn face, out of frame, mutation, mutated, extra limbs, extra legs, extra arms, disfigured, deformed, cross-eye, body out of frame, blurry, bad art, bad anatomy, Scribbles, Low quality, Low rated, Mediocre, 3D rendering, Screenshot, Software, UI, watermark, signature, distorted pupils, distorted eyes, (distorted face), Unnatural anatomy, strange anatomy, things on face, ((tattoo)), ((tattoos)),
Obviously, some of those may want to be removed if you're going for something that has been excluded.

This model merge was made during my spare time for fun, as I was curious about mixing completely different checkpoints together. I'm currently unsure if I will improve this checkpoint but I wanted to share because why not.
It's not great at extremely detailed backgrounds but I like its outcomes.
I'm fairly new to all this, so I apologise if I cannot answer questions.
Most of the images I've generated with this checkpoint are fairly straightforward to a certain extent. I haven't really tested very descriptive prompts but I would love to see if it's possible.
This checkpoint is capable of doing NSFW content, although I haven't thoroughly tested it so I do not know the limitations.
No VAE was baked into this model, so you have the freedom to pick and play your sort of style. I was using Pastel Waifu Diffusion for most of my images. I have tested it with kl-f8-anime2 and that works too.
There does seem to be an issue with hair colours. For some reason, solid colours like black often generate blue highlights. I’m unsure what causes this, so if someone knows how it can be improved I would greatly appreciate it. Thanks!
It would be great to see what sort of generations could be created from this checkpoint.
Sampling Method: DPM++ 2M Karras
Steps: 25+
CFG: 5-7 (Not really played around - Usually did 7).
Clip Skip: 2
Hires.Fix: R-ESRGAN 4X+ Anime6B
Hires Steps: 12-30
Denoising Strength: 0.4+
Upscale: 2
I also like to use 4x-UltraSharp on my images but that's definitely not required.

**Important Note! Civit renames the files, so please add "SemiReal" into the name, or it will overwrite other versions of my models.
This is my personal favourite release in my "ForYou" range. These models are created for you, the community, and more will follow. I hope you get the same pleasure from them that I do.
This "SemiReal" model produces some beautiful images and has a variety of looks and styles.
Like all my models, "hardcore" images were not a goal, but you may be able to create something from it, if that's what you're trying for.
This model does tend to produce young looking images, so please negate it in your negative prompt with something like "(infant, young child, loli)".
The example images all have the prompt details embedded.
If you like my creations, then please consider buying me a coffee. Thank you! :)
Ko-Fi


Welcome to the page of
Monster_Storm-Extrem-Tornado-RealismV1.1.0
Checkpoint Training file carried out over 3 working weeks.
All of the images are from my personal database, Via Photoshop, and completely royalty-free databases.
I provide this file for free
but I completely refuse anyone who would take credit for my work or who would come to draw money from it, loan or far.
I fully authorize you to use it for , combine, modify or merge it.
the file does not include any famous or well-known person in France or in the US or other countries,
Any resemblance to a real or famous character is totally unintentional.
Have fun.
Don't ask me for the trigger, there's no trigger
Do not ask me for Prompts of images provided
No need to ask me the time spent and the steps
take advantage of this free product and have fun.

[[Basically, I'll give you a heads up that I didn't do any (NSFW) testing. (NUDE is possible) If you want (NSFW), please merge your models separately.]]
[[[[recommend using Clipskip 2]]]] <- Never ignore it
Introducing Cutmix, a model that competes solely on cuteness. I won't write much about its usage, as I don't think models need much explanation these days.
Basically, it reflects Lora in a good way.
Her fingers don't twist like crazy, but they don't come out too well either.
The downside is that it's basically a circular model, which is a shame if you want a more mature look.
After you get the look you want, use an upscaler like Tiled VAE or sd upscale to get a better quality photo (smaller upscalers like ddetailer will work too).
Also, be forewarned that this is a heavy model. We used a model converter to make it as light as possible, but we warn you that it may be difficult to use if you're using Colab or a low-end graphics card (for fp32).

This is a Checkpoint i merged from my 3 favorite Checkpoints. Dark Sushi Mix, ReV Animated, Pika's Animated Mix.
I have been getting some incredible results with this merge and thought that it would be worth sharing with others. It is great at generating both NSFW and SFW content. Would love to see your results :D
Check my other models if you liked this one :)
Hugging Face: https://huggingface.co/BixBit11/DarkRevPikas/tree/main
Sampling Method: Euler A or DPM++ SDE Karras
(My personal favorite is Euler A)
Sampling steps: 20-30
(I use 50 for txt2img 512x512 and turn it down to 20 for img2img and increase the resolution to 1024x1024)
CFG Scale: 6-8
CLIP: 2
Hires.fix: upscale by: 1.5x -- Hires steps: 10 -- Denoising strength: 0.3
(I don't really use Hires.fix since i can generate 1024x1024 with my GPU, but if you can't then its recommended)
VAE: I strongly recommend to use this model with vae-ft-mse-840000-ema-pruned
For a more realistic image use:
photorealistic, (hyperrealistic:1.2), beautiful, masterpiece, best quality, extremely detailed face, perfect lighting,
For less realism use:
beautiful, masterpiece, best quality, extremely detailed face, perfect lighting,
My favorite negative prompt:
(worst quality, low quality:1.4), (monochrome), zombie, watermark, username,patreon username, patreon logo,

Declaration: I suggest illustrators and arts cannot be replaced by AI, although these models can accelerate design/drawing, the details, sprite-inside, visual-logics cannot be Datafication in Neural Networks.
-----------------------------——·--··c🫰c--··—--------------------------------
🔥Modill🔥 (Modern-Illustration) is a trained checkpoint to make attractive and creative illustrations/painting. It can generate some flat illustrations for both business and creative-design. Trained by 289 brilliant illustrations.
⭐️Advantages
Modill is trained by 289 brilliant illustrations from different designers/illustrators. It can draw exaggerated-body characters and raster texture.
No strictly restrictions on style. The train data includes different styles, no-overfitting can generate more special outputs.
⭐️Recommendations of parameters
Sampler: DPM2 Karras, 20~40 steps.
CFG Scale: 7-9.
Resolutions: 512*512
Negatives: poorly lit, duplicated leg, no text, one shoe, multiple head, strange face , error head, missing hand, blur, stereopsis, sex, waterpoint
*** Add some Style Lora models might generate great arts. ***
-----------------------------——·--··c🫰c--··—--------------------------------
If you have any questions related to the model or its samples, how to get started or just want to share your creations, feel free to join my discord: https://discord.gg/GgZFF3qPEB
-----------------------------——·--··c🫰c--··—--------------------------------
⚡️Appendix for X/Y/Z script

vector raster exaggerate body proportion big
Trained and merged model, is specialized for various thighhighs or pantyhose.
自炼+自融模型,对各种雪糕有一定的特化。
ZoiProlly is the original fusion style model, and the others are generalized styles.
Zoi版为最初融合的风格模型,其他均为泛化画风。
Automatic1111: SD-WebUI
DeepDanbooru/WD1.4 tagger
秋叶甜品店
You can also find this model on the hugging face.
你也可以在抱脸上找到这个模型。
Printemps/Prolly · Hugging Face

几个常用模型都升级了,于是稍微升级了下之前的 X-I-base
依旧使用的底模为 revAnimated 1.2.2
增加对比度使用了 Ally's mix IV
替换亚洲脸使用了 BRA V5
融入了自炼的 mj v5风格lora(locon),本章会附带MjV5 locon(需安装locon或lycoris插件)
Several commonly used models have been upgraded, so we have slightly upgraded the previous X-I-base
The bottom mold still used is revAnimated 1.2.2
Added contrast using Ally's mix IV
Replacing the Asian face with BRA V5
Incorporating the self-developed mjV5 style Lora (location), this chapter will include the MjV5 location (which requires installation of the location or Lycoris plugin)

一般,有老哥想要这个模ww
忘记裁剪了,明天传一个半精度
Forgot to cut, send a half precision tomorrow

ふわふわで可愛い女の子のイラストを生成するのが得意なモデルです。
The model is good at generating illustrations of fuwafuwa and cute girls.
This model is based on:
Anything V3
黑猫盛宴 | BlackCat RAT
Crowbox-Vol.1
Nostalgia-clear
SomethingV2.1

アルカディアへは センター東の通路を
通れば行ける
パスコードは kazuma_kanekoだ
そこには ニセカズマがいる
kazuma_kaneko
迭代产物,融合物
Update v4 - Added 3 more models to the mix (as per version info), fixes the issue introduced with the lora from v3 where the eyes would end up far too sparkly, and gives more detail in the backgrounds. Still works with the rcnz_niji style trigger word.
This mix was going to be Dumb Monkey v2, but ended up as a more pure anime mix, hence the acronym, "Just Another F***ing Anime" Mix
kl-f8-animev2 VAE is baked in, and both ckpt and safetensor versions are pruned to fp16
rcnz_niji style
模型不含垃圾数据无效精度,请放心下载!本模型无需一直开始HI-RES,一直开着相当于浪费时间!
插播:

如果想要更好的q版人物图,可以看看这个模型:
QteaMix 通用Q版模型 - gamma | Stable Diffusion Checkpoint | Civitai
2023.4.26
V1与ICE版本更新,这两个版本没有任何的承接关系,V1基于copper模型微调,ICE基于Anything2.1H微调,二者并无关系。
因不可抗力,目前V1版本已经下架。
2023.5.8
channel版本更新
依旧是基于Anything2.1H微调,训练集采用2233张由通配符生成的图片:
KawaICE Channel是目前最为好用的幼态体型角色特化模型,欢迎尝试!
2023.5.9
上传了一个作差LoRA,效果实际使用并不好用,还是建议下载ckp模型
本模型为幼态特化模型,但并非不能出成女等体型角色,如果达不到想要的效果,请加入“small breast”等提示词。
It is not impossible to produce adult female and other body types. If the desired effect is not achieved, please add "small breast" and other prompt words.

本模型在Anything2.1H的基础上进行训练,修改了如“Small chest”、“kawaii”等与模型主题相关提示词的权重。
This model was adjusted using the full Anything2.1N model to modify the weights of prompts such as "Small chest", "kawaii", etc. related to the model topic.
【PS:】请不要添加“masterpiece”等起手式,除非画面出现各种问题
Please do not add "masterpiece" or other prompt words
本模型的VAE没有任何问题,无需使用其他VAE
There is no problem to VAE of this model, there is no need to use other VAE
【四个版本】
V1: 效果最差图还是糊的
ICE:旧版本
Merge:适合融合的版本,如果你想要把这个模型融合到其他模型里面,推荐下载这个版本(没有上传,因为需要的不多,我这里上传太慢)
Channel:重新训练的版本,效果最好,推荐下载这个
当然了,跟所有的模型都一样,这个说明放在这里只是为了叠甲,该怎么玩怎么玩就是了。
Of course, as with all models, this instruction is just there in case something goes wrong.
你可以随意将本模型融合到其他地方,但如果你共享该融合模型,别忘了标注一下
We allow you to merge with another model, but if you share that merge model, don't forget to add me to the credits.
除此之外允许任何人复制和修改模型,但是请遵守CreativeML Open RAIL-这里是M.CreativeML Open RAIL-M相关内容:
Anyone else is allowed to copy and modify the model, but please comply with CreativeML Open RAIL-M.You can learn more about the CreativeML Open RAIL-M here:
模型可以和其他模型一样随意使用,但是请遵守所在地区的法律法规,以免造成麻烦(我们并不负责)
The model can be used as freely as other models, but please abide by the local laws and regulations, so as not to cause trouble (we are not responsible for it).
Automatic1111: SD-WebUI
Danbooru:打标器,帮助标准训练集
通配符Wildcards:没有这个东西我就不可能整出这样的训练集
秋叶甜品店:想法!
QteaMix:通过研究这个模型得到的思路!


Im back with yet another merge... as always hands good but this time i made sure yuri (girl love) works pretty darn well too, enjoy this horny mix if youd like to support me please consider donating on my kofi page :
https://ko-fi.com/horrid111

Sweet-mix is the spritual succesor to my older model Colorful-Plus. (on hugging face)
What sweet-mix performs in comparison to my older model is probably everything, seriously, check it out, i think it's really neat.
This negative prompt: extra fingers, fewer fingers, bad-hands-5, by bad-artist, (bad eyes:1.2), (misfigured pupils:1.2), (bad clothing:1.3), (undetailed clothing:1.3), ng_deepnegative_v1_75t, verybadimagenegative_v1.3, (nonsensical backrounds:1.2), (bad backrounds:1.2), (bad shadows:1.2), (bad anatomy:1.1)
These textual inversions:
- bad-artist (Not the anime version)
Clip skip: 2
And a great imagination :)
Anything-v4.5
AbyssOrangeMix 3
Protogen
CitrineDreamMix (probably)
Peachmixs
Sardonyx-Blend (introduced in v1.1)
Meinahentai (introduced in v1.2)
IvoryOrangemix (introduced in v1.3)
MixPROV4 (introduced in v1.4)
Daintymixhentaimodel (introduced in v1.4)
Jasminiquemix (introduced in v1.5)
Sirenmix (introduced in v1.6)
bbmixluci (introduced in v1.6)
Sardonyx-Blend Redux (introduced in v1.6)
IceRealistic (introduced in v1.6)
Another blend i made consisting of multiple nsfw models (introduced in v1.7)

Use the damarjati prompt to generate
"save_sample_prompt": "photo of damarjati person"
damarjati
"Chinkusha" 2.5D illustration
1.Puffy face
2.Flat nose
3.wide-set eyes
Be careful when merging... This model believes that "wolves are birds without beaks" and "distillation equipment is the most beautiful girl".
Use at your own risk and do not use this model for criminal activity.
this model includes
https://huggingface.co/nuigurumi/basil_mix
https://huggingface.co/unkounko/BalloonMix
https://huggingface.co/naclbit/trinart_stable_diffusion_v2
https://huggingface.co/Deltaadams/Hentai-Diffusion
https://huggingface.co/WarriorMama777/OrangeMixs
https://huggingface.co/syaimu/7th_Layer
https://huggingface.co/cafeai/cafe-instagram-sd-1-5-v6
https://huggingface.co/acheong08/f222
and some training with self-made images
Please follow the respective licenses for reprocessing and secondary use.
Based on the February 25, 2023 License Notice.
wide_faceokamisty
You can create skinny or curvy girls, characters from games, movies or anime work the same way. The background is also great. I recommend using my negative prompt, which will be indicated in the description of one of the pictures
It's merge of other models:
1)animeBabesBiggerABB_abbAnimebiggerbabesv2
Sampling method: DPM++ 2S a Karras
Sampling steps: 30
CFG Scale: from 8 to 10 (test yourself)
Upscaler: R-ESRGAN 4x+ from 960x544 to 1920x1088 (its work fine also for portarit images without upscaler)

Do you want to support me? Consider being a patron on Patreon to vote on train polls and access stuff early. ❤️
For my 100th upload I wanted to share my custom mix. I used walnut as base added some other models I can't remember and some of my style LoRAs.
Cause of all the NSFW styles I trained model tends to NSFW stuff to most of the time 👀
Discord server feel free to drop and say hi ^^

this model was mixed with a lot of models, i try to make it so it can produce photorealism and anime art.

此模型先是基于e9进行DB训练得到两个不同的底模,再与tmnd模型进行三模合并,并将in层和midd层以及base层重置为e9的内容物后,得到了基础版本SB-MIX-v0,此版本关于对tag的服从性异常优秀,但缺点是风格化不够明显。
接着我将SB-MIX-V0里unet的out层中的其中一份DB底模的成分替换为了新的DB底模,再将DarkSushi模型中unet的in层替换入此模型,得到了现版本SB-MIX-v1,这次操作令v1模型对tag的服从性变差了,大约只有e9的70%-80%(估算),勉强能接受的范围,但是大幅提升了模型本身的风格化表现,我认为这是有意义的。
后续会考虑进一步在unet中的in层动工,in曾全占比使用某个模型的内容还是简单了一些,我认为有可剔除和改进的空间,以改善模型对tag的服从性。至于midd层和base层我暂时不想去动它,不可控因素太多,我并没有很好的了解清楚这两个层的影响范围。
感谢bilibili的up主秋葉aaaki,以及QQ频道秋叶的甜品店,让我接触到SD-webui以及学习到许多相关知识。
尽管不会有太多人关注以及使用此模型,但我仍需要在这里叠个甲:

Someone may want the model when he or she sees the first preview image of A-Mecha Musume REN, and this one is the modified version of that.
有人可能想要A素体机娘的封面用的模型,这个是它的修改版。

Koji aims to be a general purpose model with either a focus on sfw or nsfw. Model is finetuned/trained on hassaku. Goal are easy to archive high quality images.
My Discord, for everything related to anime models.
Sponsors:
AnimeMaker.ai is a proud sponsor of hassaku, preinstalled with 300 LoRAs & 100+ full NSFW models. Render fast from ANY device. Join their community at https://animemaker.ai/

Mage.space with its amazing creators program supports all kinds of creators like me! Preinstalled with 50+ high quality models, join their discord community here!
SinkIn.ai hosts the best Stable Diffusion models on fast GPUs. You can run Hassaku at: https://sinkin.ai/m/76EmEaz

Supporters:
Thanks to my supporters Riyu and Alessandro on my patreon!
You can support me on my patreon, where you can get other models of me and early access to model versions.
_____________________________________________________
Using the model:
Use mostly danbooru tags. No extra vae needed. For better promting on it, use this LINK or LINK. But instead of {}, use (), stable-diffusion-webui use (). Use "masterpiece" and "best quality" in positive, "worst quality" and "low quality" in negative.
My negative ones are: (low quality, worst quality:1.4) with extra monochrome, signature, text or logo when needed.
Use clip skip 2 with sampler DPM++ 2M Karras or DDIM.
Don't use face restore and underscores _, type red eyes and not red_eyes.
_____________________________________________________
Every LoRA that is build to function on anyV3 or orangeMixes, works on koji too. Some can be found here, here or on civit by lottalewds, Trauter, Your_computer, ekune or lykon.
_____________________________________________________
Base model for koji is hassaku.
Black result fix (vae bug in web ui): Use --no-half-vae in your command line arguments
I use a Eta noise seed delta of 31337 or 0, with a clip skip of 2 for the example images. Model quality mostly proved with sampler DDIM and DPM++ SDE Karras. I love DDIM the most (because it is the fastest for model testing).

Pushing the brinks of semi realism. With insane clarity in images, better faces, extremely detailed backgrounds and more with CoalMix.
NOTE: ALL IMAGES SHOULD BE MADE WITH EASY NEGATVIE AND BAD PROMPT V2 ALL LINKS HERE: https://huggingface.co/datasets/gsdf/EasyNegative/blob/main/EasyNegative.pt
https://huggingface.co/datasets/Nerfgun3/bad_prompt/blob/main/bad_prompt_version2.pt
Hello people. Today I have yet another insane mix for you guys today.
CoalMix.
A semi-realistic anime mix that would take hours just to tell you guys the mix. So I won't. But I got that nice stuff for you guys today. A very good model that is probably the most realistic one yet, here is the recommended settings.
Steps: Test: 20-30. Illustration 30-150.
CFG Scale: 5+, 5 for simple prompts, 10 for advanced and long prompts. Twelve for huge prompts.
Sampler: Euler A or DPM ++SDE Karras.
Upscaler: Your pick.
Lastly, this model is very good even on 20 steps. It can create very good images, not to mention the clarity of the backgrounds of the images. In fact I ran tests on my friends on some of the images and they never even knew they were AI. This model is that good.

◼︎ Website : https://stablediffusion.vn
girlartfantashy
This model is aimed at creating a distinct, expressive style for characters that's more on the drawn side of things. It's (somewhat loosely) based off of a private model which was in turn based off the excellent Hassaku(NSFW), but has been trained a pretty good distance away from it. I've mostly trained it to create character art, but it'll still do NSFW just fine.
Major Features:
More granular control of expressions and bodytypes, with a focus on really expressive faces.
Somehow I accidentally trained it to be pretty decent with guns. Mostly tested with assault rifles. It still requires inpainting in many cases.
Tips for using:
Occasionally it'll get really stubborn with a certain bodytype and requires higher negative weighting than ideal. It probably does know how to make what you're looking for, but if it gets stuck you may have to bludgeon it a bit.
Unless you're specific with backgrounds, it will default to simple ones. A few tags should do the trick.
For a few themes (mainly cyberpunk) it reverts to the more rendered style of its predecessor. Hopefully something I'm able to fix in the future.

alinax
Model merged with intent to balance it's behavior between neutral and fairly stable, yet creative and slightly different from the "normal" sd/nai results.
There is negative embedding trained specially for this model: https://civitai.com/models/60607
Update 08.05.2023
Added 2fsVAE, it seems to me more suitable for the style of this model.
Not as faint as NAI VAE and not as overcontrasted as SD VAE.
It tends to lose details and have a bit of "ink bleeding", but nothing too crucial (IMHO) and looks like a good compromise overall.

Based on klF8Anime2VAE

Are you wanting yet another photoreal model similar to realistic vision?
A-Zovya Photoreal Ultra 1.0 is 16Gb, which is needlessly too big. Those extra GB may make a tiny difference to composition across different seeds, but very little difference to quality. There's a whole duplicate CLIP, U-Net and some lora weights in there too. I don't know why.
https://civitai.com/models/57319/a-zovya-photoreal
The original model is very similar to realistic vision, but with 14gb of useless data. With this pruned version, you'll get the same quality with a slight change in seed composition in just 1.8GB.
If you'd like to download a few hundred megabytes that will actually make a difference, use the add detail tweaker lora. It works well on any checkpoint:
https://civitai.com/models/5839
To reproduce the images similar to the original model, create generations at 384x768 then upscale 2x. Composition will be different but quality is the same. In the positive prompt:
https://civitai.com/models/8886/evelyn-nobody
And in the negative prompt - easynegative makes a huge difference to all models:
https://civitai.com/models/7808/easynegative
It's best to use this VAE: vae-ft-mse-840000-ema-pruned.ckpt

KenCanMix
This merged model is between 2.8D to realistic.
VAE is required: https://huggingface.co/stabilityai/sd-vae-ft-mse-original
Hires upscale + Dynamic Thresholding is Highly Recommended.
Recommended Parameters*:
Sampler: DPM++ SDE Karras, DPM++ 2M Karras
Steps: 25-50
Hires upscaler: Latent (bicubic antialiased), ESRGAN_4x, R-ESRGAN 4x+
Hires upscale: 1.5+
Hires steps: 15+
Denoising strength: 0.4-0.6
CFG scale: 7-10
or
CFG scale: 20-30 + Dynamic Thresholding
Mimic scale: 7-10
Threshold percentile: 99+
Mimic mode: Half Cosine Up
Mimic scale minimum: 3-7
CFG mode: Half Cosine Up
CFG scale minimum: 4-7
Clip skip: 2
*This is just how I use so far, feel free to play around and share with us any better one.
===v.1.0===
If you want Asian faces, LoRA is MUST, and the weight should be higher, try using [from:to:when] prompts. Or applying embeddings such as Ulzzang-6500
Credit to the authors of the following:

这个作者很懒,什么都没有写
Negative prompt: (bad and mutated hands:1.3), ,(bad anatomy, paintings, sketches, worst quality, low quality, normal quality, lowres,:1.3)
Steps: 40, Sampler: DPM++ 2M Karras, CFG scale: 7, Size: 512x768, Model hash: 0c94bf0354, Model: 2358-2302-超越壁垒-half, Denoising strength: 0.5, Clip skip: 2, ENSD: 31337, ADetailer model: face_yolov8n.pt, ADetailer conf: 30, ADetailer dilate/erode: 32, ADetailer x offset: 0, ADetailer y offset: 0, ADetailer mask blur: 4, ADetailer denoising strength: 0.4, ADetailer inpaint full: True, ADetailer inpaint padding: 0, ADetailer use inpaint width/height: False, ADetailer CFG scale: 7.0, ADetailer version: 23.5.6.post0, Hires upscale: 2, Hires steps: 15, Hires upscaler: R-ESRGAN 4x+

V5.0 NEW MODEL OUT : I think I found the right mix to have realism and a great NSFW. This version doesn't use VAE and doesn't need one.
This model is a mix of various furry models.
It's doing well on generating photorealistic male and female anthro, SFW and NSFW.
I HIGHLY recommend to use Hires Fix to have better results
Below is an example prompt for the v5/v4/v3/v2.
Positive:
anthro (white wolf), male, adult, muscular, veiny muscles, shorts, tail, (realistic fur, detailed fur texture:1.2), detailed background, outside background, photorealistic, hyperrealistic, ultradetailed,
Negative:
I recommend to use bad-artist, boring_e621 and EasyNegative, you can add bad-hands-v5 if you want
Settings :
Steps: 30-150
Sampler: DDIM or UniPC
CFG scale: 7-14
Size: from 512x512 to 750x750 (only v4/v5)
Denoising strength: 0.6
Clip skip: 1
Hires upscale: 2
Hires steps: 30-150
Hires upscaler: Latent (nearest)

2
Merge Model, For realistic Photo style. focusing on strengthening the skin texture and the redrawing accuracy of some facial features.
When redrawing, adjust the Text guidance parameters up to 5.0, which will help to improve the skin texture.
When using t2i, if you want to achieve a very good photo quality straight out, it is strongly recommended to use it together with LoRA Filmgirl, the face will be closer to the feeling of real asian girls.
It can also be combined with Midjourney to refine i2i, which will have a very good effect.
融合模型,追求真实的照片风格,重点加强了皮肤纹理和一些五官的重绘精度。
重绘时将Text guidance参数调至5.0以上,有助于改善皮肤质感。
在使用t2i直出的时候,如果希望直出就达到非常好的照片质感,强烈建议配合LoRA Filmgirl一起使用,面部会因为LoRA的使用更加接近真实照片的感受。
也可以结合Midjourney来进行i2i的细化,会有非常好的效果。
モデルのマージ、リアルな写真スタイルの場合、肌の質感の強化と一部の顔の特徴の再描画の精度に焦点を当てています。 再描画するときは、テキスト ガイダンス パラメータを 5.0 まで調整します。これにより、肌の質感が改善されます。 t2i を使用する場合、すぐに非常に優れた写真品質を実現したい場合は、LoRA Filmgirl と組み合わせて使用することを強くお勧めします。LoRA を使用することで顔が実際の写真の感覚に近づきます。 Midjourney と組み合わせて i2i を洗練することもでき、非常に良い効果があります。
모델 병합, 사실적인 사진 스타일을 위해 피부 질감 강화 및 일부 얼굴 특징의 다시 그리기 정확도에 중점을 둡니다. 다시 그릴 때 텍스트 안내 매개변수를 최대 5.0으로 조정하면 피부 질감을 개선하는 데 도움이 됩니다. t2i를 사용할 때 아주 좋은 사진 품질을 바로 얻고 싶다면 LoRA Filmgirl과 함께 사용하는 것이 좋습니다. LoRA를 사용하기 때문에 얼굴이 실제 사진의 느낌에 더 가까워집니다. 또한 Midjourney와 결합하여 i2i를 개선할 수 있으며 이는 매우 좋은 효과를 낼 것입니다.

This model is suitable for rural architecture with five styles of white walls and gray tiles、skeleton wall、red brick wall、wooden grille、rough stone wall. The effects can be triggered by trigger words. It can be combined with controlnet1.1 for photo repainting.
skeleton wall、red brick wall、wooden grille、rough stone wall
Black spots are a specification.
I canceled it out with my own LoRA.
boyaboya
Negative prompt: (bad and mutated hands:1.3), ,(bad anatomy, paintings, sketches, worst quality, low quality, normal quality, lowres,:1.3)
Steps: 40, Sampler: DPM++ 2M Karras, CFG scale: 7, Size: 512x768, Model hash: af427f1a7d, Model: 2358-1912-苍蟒之鳞-half, Denoising strength: 0.5, Clip skip: 2, ENSD: 31337, ADetailer model: face_yolov8n.pt, ADetailer conf: 30, ADetailer dilate/erode: 32, ADetailer x offset: 0, ADetailer y offset: 0, ADetailer mask blur: 4, ADetailer denoising strength: 0.4, ADetailer inpaint full: True, ADetailer inpaint padding: 0, ADetailer use inpaint width/height: False, ADetailer CFG scale: 7.0, ADetailer version: 23.5.6.post0, Hires upscale: 2, Hires steps: 15, Hires upscaler: R-ESRGAN 4x+
以下口胡
He drew infinite power from the scales of the azure python, feeling the dragon qi surging in his body. His eyes sparkled with golden light, as if he could see through everything. He held a long sword in his hand, with dense runes engraved on the blade, emitting a cold killing intent. He let out a long roar to the sky, swinging his sword and slashing out a sword qi, splitting the dark clouds in the air, revealing a ray of clear sky.

NSFW is supported,I think it's good, it's a good way to give back to the website, thanks to the resources of the website.
2.5D!You can read the introduction!
sampler:DPM++2M Karras
Latent (nearest-exact)
CFG:7
Sampling steps:30
Hires steps:28
Denoising strength:0.5
https://huggingface.co/embed/EasyNegative/tree/main
yesyeahvh/bad-hands-5 · Hugging Face
veryBadImageNegative - veryBadImageNegative_v1.3 | Stable Diffusion Textual Inversion | Civitai
VAE:ClearVAE - Main | Stable Diffusion Checkpoint | Civitai
Join LoRa:Shiny oiled skin 2.0 LyCORIS/LoRA - V1 LoRA | Stable Diffusion LyCORIS | Civitai
(Remember use V1!V1!)
If there are any questions, welcome to comment, I will improve.
I hope you all like it.
Meanwhile,welcome everyone to showcase their works and discuss and learn together!
At the same time, thank you to the two teachers of pixiv (YUMA, Toai R) for their guidance!

巨乳 ヌード 色白
Overview
TLDR: We are launching Vodka_V1 by FollowFox.AI, a general-purpose model fine-tuned on Midjourney V5 images. And we are sharing all the details on how we created it on our substack. Our initial version is already quite fun to work with, and thus we decided to release it. We want to continue experimentation here, so please share your feedback and expect further improvements.
Please note that model is not particularly strong in photorealism, so if that's your primary goal, you might have better luck with alternatives. It can generate some, but it takes effort, and they have a very specific style.
Outside of photorealism, we have been getting interesting results across all topics and variations.
You can read all the details about the model training process on followfox.ai (link to the post), as we can embrace the open-source nature of this community. You can recreate the process, see exactly how we got here, and provide feedback and suggestions on individual aspects of the protocol.
We did some testing but hoped to hear more and update this based on the feedback from the community:
CFG ranging from 3-6 work well. For realistic human generations, lower CFG works much better, indicating over-training. For more creative generations where realism is not needed, a CFG value of 7 also works well.
Low step counts (0-30) seem to generate less interesting results, but starting from 40 and to 150, everything seems equally worthy.
If a prompt is overly lengthy, lower CFG values seem better, or otherwise, images look fried.
Almost all samplers seem to generate interesting results.
There is a ton to try and improve from here, from a few long-hanging fruits, such as lowering the learning rate to make the model less fried to experimenting with captioning images, segmenting by different classes and weighing them by the current weakness, cleaning the dataset, using more advanced training protocols, so on and so on.
For now, we will release the model and observe what happens. If we see some traction and interest, we will continue iterating. So please share your thoughts with us!


It features strong contrast, bloom Effect and color tones
Based on Legendary Dalcefo, but a lot has changed. not suitable for hard NSFW
I don't recommend negative embedding in most cases
because it has a huge impact on color and figure
Still in very early stages, but have fun playing with it 🙂
////////////////////////////////////////////////////////////////////////////////////
Recommended Settings - VAE is already included
Clip skip : 2
Hires. fix : R-ESRGAN 4x+ Anime6B / Upscale by 1.5+ / Hires steps 14 / Denoising strength: 0.4
Adetailer / Just select face_yolo8n.pt
Sampler : DPM++ 2M Karras / DPM++ SDE Karras / UniPC
CFG : 8 Steps : 25
Prompts
(best quality, masterpiece), looking at viewer,
Neg : (worst quality, low quality)
////////////////////////////////////////////////////////////////////////////////////
Do you like my work? check out my profile and see what else!
And A cup of coffee would be nice! 😉
////////////////////////////////////////////////////////////////////////////////////
For anything other than general personal use, please be sure to contact me
You are solely responsible for any legal liability resulting from unethical use of this model

This is my first merge upload, and is simply the product of mixing a few of my favorite models that I thought might look nice together. I was pretty happy with it so I decided to upload it.
Merged models:
Fantastic Mix V4
ChikMix V3
ZemiHR V2
This model can produce very nice results with prompts as simple as "A female soccer player" and can sometimes produce nice results before upscaling is even applied yet.
For the examples, I tried making a few sample images of:
Samples where I add a lot of other (hidden) prompts with various quality trigger words like "masterpiece", "best quality", etc. to give an idea of what's possible when you sculpt the prompts a little.
Simple (visible) prompts of various different things with no LoRAs. Some of these aren't perfect, but are just demonstrating what you can do with simple prompts and nothing extra.
Using only a simple (visible) prompt like "A 21 year old female" along with a few LoRA's and their trigger words to let the LoRA do its thing to show compatibility with a few LoRA's.
Despite the name, it's capable of a wide variety of images, which can hopefully be seen from the examples. I tried to provide some variety to the examples.
Settings for (most) examples:
Clip Skip = 1
VAE: vae-ft-mse-840000-ema-pruned (Don't forget)
CFG Scale = 7
Sampling Steps = 20
Height, Width = 512 x 768, 768 x 512
Sampling Method = DPM++ SDE Karras
Upscaler = 4x UltraSharp
Denoise Strength = 0.5
Upscale by = 2

No special reason for the north dakota name, just wanted something to call it and it seems flat enough to be North Dakota. It primarily makes fine art painting style looking images

This model is trained base on my own artworks, used BRA4 as a base model, and merged with Counterfeit v3. You can find my art at pixiv:
https://www.pixiv.net/users/18736174
So actually, it is not a pure trained model, but the necessary part of it is trained. The original trained model is not so suitable for general use, and also I want to keep it, so it was not uploaded here.
The trainning progress is focus on strongly copy my art style, while the merge progress is focus on enhance model usability. I guess the model now is close to my style with high usability.
Hope you like this model and my aesthetics!
If you're sharing it, credit me.
此模型是基于我的个人绘画作品训练的,基础模型是BRA4,并融合了一些Counterfeit V3。你可以在PIXIV查看我的个人页面:
https://www.pixiv.net/users/18736174
所以,这并不完全是一个训练的模型,不过训练的部分对于这个模型来说是关键的。我训练出来的原始模型不适合通常使用,并且我个人也想要保留它,所以就不上传原始模型了。
训练的过程目的是要复制我的画风,并且在融合的过程中增加模型的通用性。我认为这个模型现在已经可以在接近我的画风的情况下有很好的可用性。
希望你喜欢这个模型和我的审美。
如果要分享这个模型,请提及我。

日常产出
实在不知道名字咋起了,正巧刚才打印机没墨了,就这样,ღ( ´・ᴗ・` )比心

*Example images' prompts in InvokeAI format, not A1111 format. If you don't use InvokeAI, don't copy/paste my prompts without first adjusting the syntax.
Animated version is less heavily anime and thus more general-purpose. Anime version is more focused towards anime, and has some extra specialization in chaos, badassery, and scenery, and much less tendency for uncanny valley. However, both primarily consist of the main 526Mix.
USAGE TIPS, BEST PRACTICES, AND SETTINGS (Anime version):
CFG at 6 to 7 recommended, as this model is a tad overbaked.
As this model is still mostly non-anime by percentage, you'll want to keep anime somewhere in your prompt if you want an actual anime style.
The recommended negative embeddings are negative_hand, and then either a choice of bad-artist (the base version), <neg-anime>, or <neg-sketch-2>. negative_hand doesn't interfere with the model and has an okay success rate. bad-artist has less effect on model imagination than <neg-anime> or <neg-sketch-2>, and provides brighter and more colorful results, but doesn't have as high a detail level. <neg-anime> or <neg-sketch-2> are the opposite. More effect on imagination, but more detailed and less change in composition.
Other negative embeddings (e.g. bad-artist-anime, bad-hands-5, bad_prompt_version2) are generally not recommended, as they impact art style and model expressiveness and have little, if any, actual benefit.
When not using any negative embeddings, negative_hand aside, using (low quality, worst quality, lowres) with a 1.3 or 1.4 weight does the job for most prompts if you get any subpar definition or color.
This model uses some LoRAs from merging in Cusp of Serenity, so the same advice of putting rainbow in your negative prompt to kill unwanted extra colors, or backlighting to kill weird lighting effects applies here. They should be low enough to not be a constant problem, but it's good to keep in mind just in case.
Certain action scene style prompts like those in the examples may have a tendency to put titans somewhere in the background. If you don't want that, putting titan, giant in the negative prompt seems to help.
Upscaling via img2img / High-Res Optimization in InvokeAI is ideal, especially at a strength like 0.47-0.55.
This model uses the Waifu Diffusion 1.4 VAE with the pixel layer modified for -6% contrast. img2img at low strength may reduce quality unless you swap the VAE.
USAGE TIPS, BEST PRACTICES, AND SETTINGS (Animated version):
negative_hand and bad-artist are the only negative embeddings I can comfortably recommend using for this model, and not even that is a requirement. <neg-anime> or <neg-sketch-2> are also great, but tend towards a semi-realistic style in this model, so be wary of the uncanny valley if you use them.
To liven up color and lighting (when not using a negative embedding), I suggest putting desaturated and pixelated in your negative prompt with 2 or 3 units of down-weighting (that means [[[desaturated]]], [[[pixelated]]] in A1111 UI, or desaturated---, pixelated--- in InvokeAI).
To lean output more towards an anime style rather than semi-realistic, include anime in your prompt. Put realistic in your negative prompt to further lean towards 2D, or by the front of your positive prompt to lean more 3D.
Example images were generated in InvokeAI, so you'll have to use your UI's weighting syntax (which means the + and - in my prompts likely won't do anything for you unless you're using InvokeAI).
The goal of this model was to anchor 526Mix's whimsical and artistic personality into anime. 526Mix can do a pretty cool anime style (and other 2D styles), but it can be a bit unreliable at times. This simple mix increases the reliability, depth, and nuance in 526Mix's anime and anime-esque capabilities.
This model will be great for:
People who want an anime aesthetic that is different from other SD 1.5 models
People who are more distant, casual enjoyers of anime, who might find this model more welcoming than one that's heavily leaned to modern anime art only
People who like more classic anime styles, ala Voltron and Ghost in the Shell
People who like generating in 2D and semi-real styles and liked 526Mix, who will probably enjoy the better lighting and touch of wackiness in this version
I'm not big on anime myself, so this was more of an experiment. If you liked 526Mix's variety and personality (and cozy interior design), and also like anime, you'll probably have fun with this.
This model is a straightforward mix of 526Mix-V1.3.5, and Nerfgun3's Macaron Mix, the latter having had the noise offset added at 0.70 multiplier. This is done with a weighted sum at a 0.3 multiplier with Macaron Mix. I always like Nerfgun3's art and embeddings, so I felt I could trust that model to be fairly in line with my own creative desires and expectations.
As always, I suggest going to the source models for the full experience, and Nerfgun3's Macaron Mix and Newartmodel4 aren't exceptions here.
Example images were generated in Invoke AI with the model converted to Diffusers format, hires fix on (0.45 strength, works like img2img), and the sampler DDIM (unless listed otherwise). This means unless you use Invoke AI, you likely won't be able to recreate my images exactly. Just learn from the prompts and modify the weighting in prompts as needed for the UI you use (if you use the A1111 UI, any (plus sign)+ is equal to one set of parentheses).

You can now run this model on RandomSeed 🙂

Updated - v5: Added Am I Real, Analog Madness, and TangBohu and the amazing add_detail lora at weight 1 to the mix. I think the details in the backgrounds are looking much better now, with the faces looking as good as ever. If you are looking to "calibrate" the model on a UI that isn't a1111, this photo has a prompt that should allow for full replication
Following on from Gorilla With A Brick, I've merged in 10 more photorealistic models at various weights, and some more noise offset to create something that when prompted for photorealism will make you go "I Can't Believe It's Not Photography". It will happily create CGI characters and awesome landscapes as well.
As always, pruned to fp16, and the VAE baked in (SD-v2 840000)
rcnz_hqr style
Official Doc v1.2 :
Updated the : 9/5/2023
https://docs.google.com/document/d/1ntSe2adowamw7t7mMn98GHRNSKamJ9eBLGVWWF_kOj0/edit?usp=sharing
Update :
Simplify for understanding.
Bug correction. (A lot)

create your fantasy, your imagination is limitless!
still in beta. :)
Join my discord server for any questions please thank you!
newest updates will be released in my discord server

Better characters, More details, and more with VewniumV2!
After mixing for god knows how long, I finally came up with a better looking mix than VewniumV1. This mix still goes along with the anime like style of VewniumV1, however it makes its characters look better, adds more details, and as well as that the color palette of VewniumV1 is still there. Here are the recommended settings for this model. As well as the mix itself.
Sampler: DPM++ SDE Karras
Steps: 40 for test, 50+ for illustration (with Xformers it will still be fast)
CFG Scale: Your Pick.
Upscaler: Latent Nearest Exact
Prompts: Depending on CFG Scale, they can be complicated (I recommend 8 as well as 150 steps for complicated prompts), or small, (CFG Scale of 6 or below and 50 steps is recommended.)
Mix:
VewniumV1: 20%
AmbroisaFusion: 60%
Anything V4.5: 20%

I wasn't satisfied with the current Cirno LoRAs out there, so I decided to create my own. I have chosen to use 1024 dim to capture every detail perfectly.
It can also do yellow Cirno.
cirno
A Model guy
DavidThis is a rather old model of mine, so it might be faulty in some aspects. Most notably, it sometimes produces nonsensical faces and creates textures where they shouldn't be, but you should be fine as long as you use recommended settings.
Sampler: DPM++ 2M Karras, DPM++ SDE Karras
Steps: 20+
CFG Scale: Anywhere between 4 to 11, beyond that I did not test, but I doubt you'd be using values outside of that bracket anyway. Lower scale values seem to be more "creative" at the cost of producing more muted colors. Also, higher CFG scale values tend to produce aforementioned errors more often (for instance, on Euler a with 20 steps and no hires.fix)
Hires.fix: on, upscaler either any of the Latents or R-ESRGAN 4x of your taste. Latent is more creative, R-ESRGAN is less prone to nonsense generations. Use denoise strength in the range of 0.55 to 0.75 for Latent and 0.3 to 0.75 for R-ESRGAN.
Clip Skip: 1 or 2, the effect is similar to CFG Scale with 1 being more creative and 2 having deeper contrast and more popping colors (all example images made with Clip Skip 2).
VAE: the one from the base SD 1.5 model. I didn't bake it in just in case you want to use something else with the model.
This is a merge model of a couple models and loras, I can't remember each one but I believe the base was made of Mistoon.
This was going to be a personal model, but the frens on Baest were interested in it, so everyone gets it.
It works well with the Anything VAE, if your generations happen to be bland or colorless or have purple artifacts.

