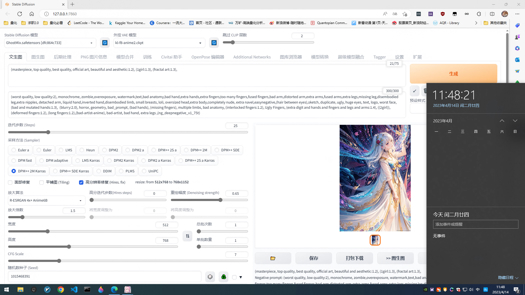
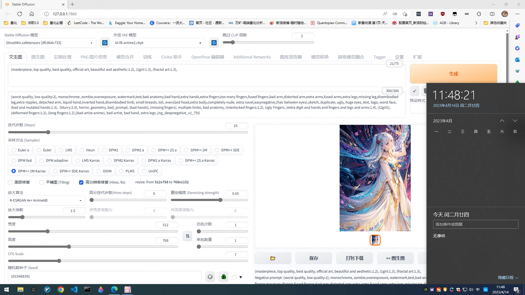
2023.4.16 GhostMix-V1.1
UPDATE DETAIL(更新说明)
Improve the stability while using GhostMix on charactor, and make the face more like real man. Improve the quality of the model.If you like my model, feel free to upload the generated pictures to share with us. It will help me for the next version of GhostMix, thanks again.
提升了GhostMix在生成人物时的稳定性,使得人脸更逼真。模型质量进一步提升。如果觉得我的模型不错,欢迎上传生成的图片分享,会队我调下一个版本GhostMix有很大的帮助。关于图片复现问题可以看3.11的下文,谢谢。
2023.3.11 GhostMix-V1.0
Introduction(中文简介在下面)
First of all , I want to thank all the people who use this Checkpoint. And this is my first Checkpoint.All the sample image can be reproduced. This Checkpoint works well on both SFW and NSFW.THE NSFW PART IS VERY GOOD!!!
I uploaded this Checkpoint yesterday and from yesterday to today , I am still trying all the possibility of this Checkpoint. So if you try the model and find some good promts , I hope you can upload it and share with me, it will help me for the next version of GhostMix, Thank you agian!
Recommend Some Promts:
Fractal Art(highly recommend,awsome)
(masterpiece, top quality, best quality, official art, beautiful and aesthetic:1.2), (1girl:1.3), (fractal art:1.3),
Realistic Art-Girl & Flower field
((masterpiece, best quality)), 1girl, flower, solo, dress, holding, sky, cloud, hat, outdoors, bangs, bouquet, rose, expressionless, blush, pink hair, flower field, red flower, pink eyes, white dress, looking at viewer, midium hair, holding flower, small breasts, red rose, holding bouquet, sun hat, white headwear, depth of field,
Color Art
(flat color:1.3),(colorful:1.3),(masterpiece:1.2), best quality, masterpiece, original, extremely detailed wallpaper, looking at viewer,1girl,solo,floating colorful water
Realistic Art-Nude Girl(NSFW-recommend)
(masterpiece, top quality, best quality, official art, beautiful and aesthetic:1.3), illustration, beautiful detailed eyes, (1girl), (nude),detailed nipples,huge breasts,puffy nipples, oniomania, erotic,beautiful detailed pussy,soft breasts,upper body
VAE&Textual Inversion:
VAE: kl-f8-anime2 or vae-ft-mse-840000-ema-pruned(anime suggest: kl-f8-anime2)
Textual Inversion: ng_deepnegative_v1_75t, easynegative
About Image Reproduction:
Some user said that they can not reproduce my result.Maybe the setting goes wrong.I just reproduce my cover image. If you want to reproduce my result, Checkpoint Model,Postive Promt,Negative Promt,Textual Inversion,Sampler Steps,Sampler,CFG,Resolution,Seed , ALL the things should be the SAME! Then be careful if you open controlnet or lora ,don't make them influnence your result.
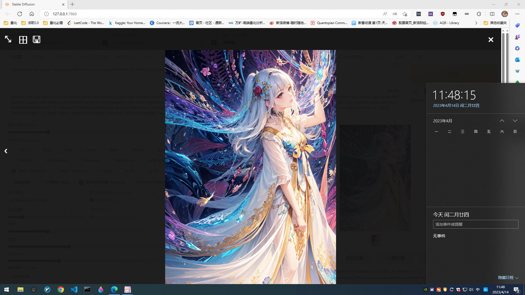
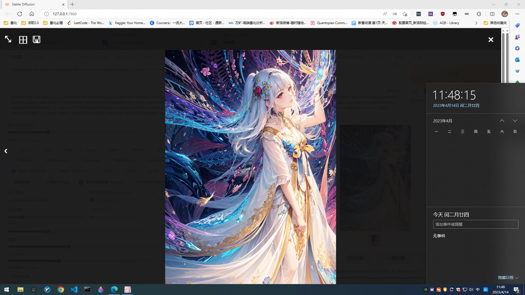
中文简介
首先感谢每一个使用这个Checkpoint的人,这是我融的第一个Checkpoint。所有样图自测都可以复现。SFW和NSFW的图都挺漂亮的,NSFW的图非常棒。这个模型昨天上传到今天,我一直在尝试这个模型的可能性。希望使用这个Checkpoint的朋友们,如果你试了,觉得有不错Promts,欢迎上传图分享,让我也了解一下这个Checkpoint的可能性,也可以帮助我调下一个版本GhostMix,再次感谢。
推荐Promts:
分型艺术(超级推荐,必出好图)
(masterpiece, top quality, best quality, official art, beautiful and aesthetic:1.2), (1girl:1.3), (fractal art:1.3),
真实风格-少女与花海
((masterpiece, best quality)), 1girl, flower, solo, dress, holding, sky, cloud, hat, outdoors, bangs, bouquet, rose, expressionless, blush, pink hair, flower field, red flower, pink eyes, white dress, looking at viewer, midium hair, holding flower, small breasts, red rose, holding bouquet, sun hat, white headwear, depth of field,
色彩艺术
(flat color:1.3),(colorful:1.3),(masterpiece:1.2), best quality, masterpiece, original, extremely detailed wallpaper, looking at viewer,1girl,solo,floating colorful water
裸女(色图-推荐)
(masterpiece, top quality, best quality, official art, beautiful and aesthetic:1.3), illustration, beautiful detailed eyes, (1girl), (nude),detailed nipples,huge breasts,puffy nipples, oniomania, erotic,beautiful detailed pussy,soft breasts,upper body
VAE&Textual Inversion:
VAE:kl-f8-anime2或者vae-ft-mse-840000-ema-pruned(动画风建议kl-f8-anime2)
Textual Inversion:ng_deepnegative_v1_75t,easynegative
关于图片复现:
有同学好像没法复现我的图,可能是设置有点问题,刚刚我才把头图给复现了。注意几个点:Checkpoint 模型,正向Promt,反向Promt,Textual Inversion,迭代步数,迭代方法,CFG,分辨率,随机种子都必须一模一样!然后复现的话,要把controlnet和lora关掉,怕影响复现。