A
файл на civitaiстраница на civitaitest

test
Trained with +5k HD Pictures
Use Trigger word and negatif prompt like me for good results
V3 : Trigger Word Avalable (some work better than others), better bad body result but you may still bad result sometime, be patient.
Recomanded Setting :
Not use : "Restore faces" if you upscale
Upscaler : Lanczos x1.3-1.5
CFG Scale : 4-7 (low value for difficule possiton)
Have fun and don't hesitate to share your images !
Credite if you merge this model.
vixenFucked_rabbit_earsOverturned_stylecum_on_facefucked_brake_sexclose_up_sexfucked_missionary_stylelick_the_dicksuck_flip_styleshow_assplay_with_dickonlyfansovertuned_analfucked_missionary_style_povsuck_dick_povfuck_boobscum_on_face_povfucked_cowgirlfucked_doggy_style_anal_povsuck_dick
Combination between Ether Blu Mix 3.2V + DefbeaCF3AR_mix
I recommend using this VAE for better color, kl-f8-anime2 VAE

Steps: 20,
Sampler: DPM++ 2S a Karras,
CFG scale: 7,
Denoising strength: 0.5,
recommend prompt: (masterpiece),(best quality),(ultra-detailed), (full body:1.2),simple background,white background 1girl,chibi,cute,
bad prompt: (low quality:1.3), (worst quality:1.3),
enable_hr: true
Hires upscale: 2,
Hires steps: 20,
Hires upscaler: R-ESRGAN 4x+ Anime6B
Clip skip: 2,
VAE: kl-f8-anime2.vae.pt
cutechibi
Warning: contains both safe and unsafe content, if it can be called that.
This model was trained by me in Dreambooth on 14 photos.
Teletext is a network service of a television network that allows you to watch text and images on TVs with decoders. Teletext works in broadcast mode and provides information on various topics, such as news, weather, TV programs and subtitles. Write only the simplest prompts (due to the small dataset) and do not forget the trigger teletext. Often a negative prompt breaks the style, try to control it or not use it at all.
Contains noise offset.
警告:包含安全和不安全的内容,如果可以这样说的话。
这个模型是我在Dreambooth上用 14 张照片训练的。
电视文字是电视网络的一种网络服务,它允许你在有解码器的电视上观看文字和图像。电视文字以广播模式工作,提供各种主题的信息,例如新闻、天气、电视节目和字幕。只写最简单的提示(由于数据集很小),不要忘记触发器 teletext。负面提示经常会破坏风格,尽量控制它或者干脆不用它。
包含 noise offset。
Предупреждение: содержит как безопасный, так и небезопасный контент, если его можно так назвать.
Эта модель была обучена мной в Dreambooth на 14 фотографиях.
Телетекст — это сетевая служба телевизионной сети, которая позволяет смотреть текст и изображения на телевизорах с декодерами. Телетекст работает в режиме широковещания и даёт информацию о разных темах, например, о новостях, погоде, телепрограммах и субтитрах. Пишите только самые простые промпты (в связи с маленьким датасетом) и не забывайте триггер teletext. Часто негативный промпт ломает стиль, старайтесь контролировать его или не использовать вообще.
Содержит noise offset.
teletext
negative prompt:EasyNegative, (worst quality:2), (low quality:2), (normal quality:2), lowres, normal_quality, ((monochrome)), ((grayscale)), skin_spots, skin_blemishes, age_spot, signature, ((watermark)), text, ((bad_hands)), bad_anatomy,
Steps: 20,
Sampler: DPM++ 2M Karras,
CFG scale: 7,
Denoising strength: 0.5,
Hires upscale: 2,
Hires steps: 10,
Hires upscaler: R-ESRGAN 4x+ Anime6B
Clip skip: 2,

This is my third merge. With my new SD base I can now comfortably merge with my weight recipe.
PNG INFO DIDNT STICK
Please use DPM Karras / UniPC / 20ish steps /
dynamic threshold cfg 12.5 mimic 7 / 512x512 highres x2
------------------------------------------------------------------------------------------------
It's called imPURErity cos it's 100% a totally wholesome anime merge. It can ONLY definitely do pure wholesome content.
The style is heavily anime with little realism. I like using Pastel waifu VAE as it's probably baked in if i didn't forget. CLEARVAE and CLEARVAE nanless is nice with it too.
Does good quality anime generations
???
profit

I will be working with this model more.
The progress I've been making this is pretty nice, if there any suggestion guys of what other model's should I merge it with?

Personal merged of a bunch of diferent models. cannot remember.

another try

Includes a complicated Lora mix, berry mix, and some other back mixed toys.
What this means is: Vox+Western Loras of Lykons + our Anime Model, plus some of the Neneko Splat/Eggnog line we've been working on. Beyond that we're unsure.
This is our attempt at a MOSTLY compatible with loras base model, and is not intended to rival with AnyLora because Lykon is so much cooler than us.
We're starting a new initiative with our models: Fighting for accessibility in Art for not just everyone but specifically mental and physical disability spaces. AI art isn't JUST a tool, it's a new way of expression for those unable to do so before.
PLEASE NOTE: IMAGES MAY NOT SHARE THE SAME FILE NAME AS MODELS THAT ARE UPLOADED. "KILKENNY EGGNOG" IS THE SAME AS CEL-FLAT, JUST THAT THE ORIGINAL HF FILE THAT WAS CKPT DIDNT GET THE SAME NAME UNTIL AFTER I DOWNLOADED IT FOR CIVIT!
CEL FLAT ON HF: https://huggingface.co/Duskfallcrew/Kilkenny-Mix-CelShade (DEMO SPACE INCLUDED) https://huggingface.co/spaces/EarthnDusk/KilkennyMix
Will you help us with our target market research? : https://forms.gle/N1EQwZmZzdHMzP8H8
Join our Reddit: https://www.reddit.com/r/earthndusk/
Funding for a HUGE ART PROJECT THIS YEAR: https://www.buymeacoffee.com/duskfallxcrew / any chance you can spare a coffee or three? https://ko-fi.com/DUSKFALLcrew
If you got requests, or concerns, We're still looking for beta testers: JOIN THE DISCORD AND DEMAND THINGS OF US: https://discord.gg/Da7s8d3KJ7
Listen to the music that we've made that goes with our art: https://open.spotify.com/playlist/00R8x00YktB4u541imdSSf?si=b60d209385a74b38

2023.5.17
更新了reality 3.0。这个版本在减少模型体积同时,图像真实感与面容美感进一步提升。
Updated reality 3.0. In this version, while reducing the size of the model, the realism of the image and the beauty of the face are further improved.
2023.4.21
我将胶片风Lora小比例融合进了Fantasy模型中,优化了此模型下皮肤的质感。但请注意,要获得完美的胶片质感,仍需要搭配胶片风Lora使用,只是使用比例可以降低0.1~0.15左右。
Fantasy 2.0模型更偏幻想风格一些,Reality 2.0模型更偏写实风格一些。两个模型质量都不错,大家可以根据需求下载使用。
2023.4.20
更新了reality2.0版本,这个版本相比之前两个版本,较大幅度提升了皮肤和样貌的真实感。建议在生成人像时,搭配胶片感Lora(1girlmix)使用,真实感更佳。
同时最重要的,新模型搭配兔狲Lora使用,生成兔狲逼真图像的成功率大幅提升!(没错,我搞这个模型,其实主要是为了训练猫猫)
chilloutmix模型与本模型的reality版本、fantasy版本的对比:
Comparison between the chilloutmix model and the reality and fantasy versions of this model:



我比较推荐用reality版本的模型,在色调、颜值和真实性上比较平衡。建议将clip skip设为1,这样生成的图会更美观。
I recommend using the reality version of the model, which is more balanced in tone, appearance and authenticity.
本模型由多个checkpoint模型合并而来,具体有哪些我也记不太清了。以下是MoonMix与chilloutMix模型在生成人像时的一些对比。总的来说,MoonMix相比chilloutMix,真实感和锐度有所下降,但美感与丰富度有所提升。
This model is the result of merging several checkpoint models. I can't remember exactly which models there are. Here are some comparisons between MoonMix and chilloutMix models in generating portraits. In general, MoonMix is less realistic and sharper than chilloutMix, but the overall beauty and richness is improved.
演示样例中所使用Lora模型“1girlmix”可以在此处获取:https://civitai.com/models/33208/lora
The Lora model "1girlmix" used in the demo example is available here: https://civitai.com/models/33208/lora







12414124
123123
Simply a merger between RevAnimated v1.2.2 and MeinaPastel V4 that I tried to experiment with for my group of friends (sup /WWA/?). It probably wont be updated as I have no idea what i'm doing when it comes to this sort of thing, and I take ZERO credit for this beyond mashing two existing models together. No VAE needed.

Defalut prompt
best quality,yaju-senpai
lowres, bad anatomy,bad reg,bad regs,bad hands,error, missing fingers,extra digit,fewer digits, cropped,worst quality,
low quality,,signature,letterbox, watermark, username, blurry, artist name,, liquid body,liquid tongue, disfigured,
malformed, bad shoes,fused shoes, more than two shoes, Cubism, pablo piccaso,disney
yaju-senpai
A bit of detail with a cartoony feel,
and it keeps getting better!
////////////////////////////////////////////////////////////////////////////////////
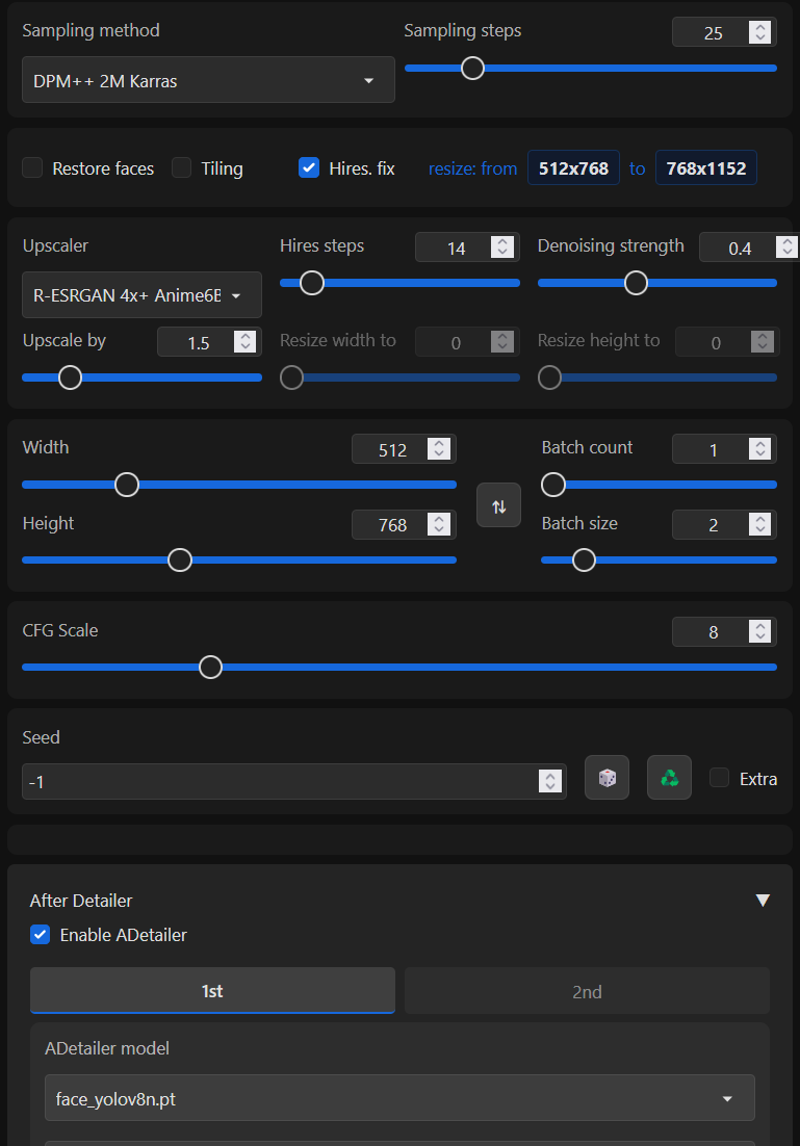
Recommended Settings - VAE is included starting with Alpha2
Clip skip : 2
Hires. fix : R-ESRGAN 4x+ Anime6B / Upscale by 1.5+ / Hires steps 14 / Denoising strength: 0.4
Adetailer - face_yolo8n.pt - Improves the blurriness of the character's eyes
Sampler : DPM++ 2M Karras / DPM++ SDE Karras / UniPC
CFG : 8 Steps : 25
Prompts
(best quality, masterpiece)
Neg : (worst quality, low quality)
////////////////////////////////////////////////////////////////////////////////////
Do you like my work? check out my profile and see what else!
And A cup of coffee would be nice! 😉
////////////////////////////////////////////////////////////////////////////////////
For anything other than general personal use, please be sure to contact me
You are solely responsible for any legal liability resulting from unethical use of this model

Aesthetics-focused anime finetune. Waifu Diffusion 1.5-based, inherits that license.
Experimental variants can be found here.
Images may be overly bright; if you find this to be the case, consider using this extension.

Support me and visit https://ko-fi.com/darkseal
This is my DarkFruit model merge block weighted with mistoonAnimeV10 for the style. Still has some duplication and body dismorphic issues. I have not really tried to fix the body parts, I might try again... Right now I just let my loras and locons take over to correct the issues for me. Good Luck everyone!

Potassium rich latent diffusion models trained to the likeness of Banano Chan. The digital waifu embodiment of Banano, a feeless and super fast meme cryptocurrency.
banchan
Just a small fusion of Somethingv2 and RuviMixV1, still a working progress but I will someday make it work

This is censored language for POLTERBITCH aka Poltergeist.
It's an in house nod to some of our alter's truths, and it's kind of a joke for Beetlejuice fans.
THIS IS AN ILLUSTRATION - COMIC MIX and there's several versions of this and you'll note that there is only ONE DEMO SPACE FOR IT ON HF so far - but give us time we're working on it!
VAE: We use KF-L-Anime, but it is entirely up to you. We can provide one if you need
DOES THIS DO NSFW: IT MAY WE ARE NOT SURE, THERE IS BERRY MIX IN IT AND OTHER MODELS - BUT IT WAS NOT INTENDED FOR THIS, WE MAY MAKE A MORE NSFW UPDATE TO THIS IN FUTURE IF YOU NEED IT.
POODABEEP DEMO/HF REPO: https://huggingface.co/EarthnDusk/Pooda-Beep-Mix / https://huggingface.co/spaces/Duskfallcrew/PoodaBeep-Mix
Will you help us with our target market research?: https://forms.gle/N1EQwZmZzdHMzP8H8
Join our Reddit: https://www.reddit.com/r/earthndusk/
:Funding for a HUGE ART PROJECT THIS YEAR:: https://www.buymeacoffee.com/duskfallxcrew / any chance you can spare a coffee or three? https://ko-fi.com/DUSKFALLcrew
:If you got requests, or concerns, We're still looking for beta testers: JOIN THE DISCORD AND DEMAND THINGS OF US:: https://discord.gg/Da7s8d3KJ7
:Listen to the music that we've made that goes with our art:: https://open.spotify.com/playlist/00R8x00YktB4u541imdSSf?si=b60d209385a74b38

Super Merge

guttonerdinho1
Seraph_Mix is meant to be a beautiful and colorful/bright hentai mix.
Something with the Civitai website broke with the original model, sorry to those who have it, but hey, now you have exclusive models! This is a Re-Upload, and has been fixed/improved.
-
-
It is recomended to use (512x768), (Euler A), and a (CFG Scale of 7)
(768x768) images are still good and possible :
Example Generation
Positive prompt: detailed anime visuals Advanced stunning epic magical picture full of details, majestic scene, insanely detailed, beyond beautiful ethereal majestic illumination, simultaneous high low frequency, simultaneous contrast, stunning artwork, gradient hues, beautiful atmosphere, layered topography, (seraph)
Negative prompt: (worst quality, low quality:1.4), easynegative, bad anatomy, bad hands, cropped, missing fingers, missing toes, deformed, disfigured, distorted face, mutation, ugly, poorly drawn hands, out of focus, monochrome, symbol, text, logo, door frame, window frame, mirror frame,
Steps: 30, Sampler: Euler a, CFG scale: 7, Seed: 3771725356, Size: 768x768,
Use the prompt above, its pretty cool!
-
LORA's from "ddp12" are pretty cool.
I also recommend using this LORA : "BetterHands" - By Envy
-
Thank you to the creators of both Yesmix, and AOM3, without them i would not have been able to create such a beautiful checkpoint merge.
Thank you the creators and mods of Yodayo, AI generation website, as without them i would not be here today making good images and checkpoint merges.
-
Special thanks to you, for downloading! : D

--
中文 | English
--
*目录是:
简介
诞生缘由
效果实例
模型参数
*不论我接下来吹得多好,模型具体表现如何因人而异。(说实话我自己心里也没底,但是用了有几天了)
--
*Table of contents:
Introduction
Background information
Example of performance
Model parameters
*Regardless of how well I describe it later, the specific performance of the model may vary from person to person. (To be honest, I am not completely sure myself.)
--
CreationMix Checkpoint是基于多个Checkpoint混合的模型,旨在解决不同画师、作品和需求下的生成效果问题。其词条齐全、权重合理,能够在日常使用中生成质量较高的图片,并在使用LoRA模型时保持画风一致。同时,在LoRA的训练有限时也能提供较好的表现,是一个较为实用的Checkpoint模型。
CreationMix Checkpoint is a model that combines multiple Checkpoints to solve the problem of different artists, styles and requirements in generating images. It has complete vocabulary and reasonable weight, which can generate high-quality images in daily use and maintain consistency in style when using LoRA model. Additionally, it can also provide good performance even with limited training of LoRA, making it a practical Checkpoint model.
--
诞生的缘由是这样的:
有的画师作品比较少,单张图迭代次数也少的话很难保证LoRA模型训练效果,但是迭代次数过多又会过拟合。这时,我训练出来的LoRA模型的词条通常很难把握。
有的画师作品里的人物姿势很反常,尤其是R18作品里体位千奇百怪,原图筛了又筛还是不满意。这时,我训练出来的LoRA效果会很不理想。
有的画师作品细节非常多,一般的2D Checkpoint模型很难出效果,但2.5D的模型通常细节会很丰富。
有的画师作品较为立体,2D Checkpoint模型很难出效果,这时候2.5D的模型表现通常会更好。
有的画师作品较为平面,这时候2.5D的表现会很糟糕,2D模型相对而言表现会更加优秀。
没有不好的意思奥,主要是说说我在使用各个Checkpoint的过程中遇到的种种难处:
DosMix、PerfectWorld、ChikMix、BugerMixSoftPastel、Refslave、NyanMix之类的就不用说了,本就有自己的一套画风,用来发模型的预览图显然不合适。
我的LoRA训练的效果实在没法看的话不会发布,在其能够体现出画风时才会公开,但不能保证每个都训练的到位。AnyLora的效果令我震撼,对LoRA效果的表现很精确,以至于在一些时候很好地暴露了训练上的缺点(这往往是我训练出的LoRA不够好导致的);此外,由于大佬对模型的修剪,在细节的体现上对俺不是很友善,我个人的水平很有限;最为次要的,平时的画风不是很对我味口,我个人还是比较喜欢精致些的画风。
YesMix在部分2.5D画师的表现上比较吃力。
CetusMix虽说是我以前常用的模型,但是用来体现画风不够合适。
在我认为,画风模型的预览图,应该要能做到以下两点:
与画风较为贴切,合理表现画风的效果,能够让人一眼看出这是哪个画师的画风。
能够让人眼前一亮,朴实的Checkpoint出的图显然能体现出画风,但是没有实际使用时的参考意义。
所以我就在想,要是有这么一个Checkpoint模型:
词条足够齐全,词条权重比较合理。
在日常使用时出图比较符合我审美,能够作为我的主要Checkpoint。
没有过于立体的五官,人物画风较为中立,不会偏幼或者偏成熟。
在没有LoRA时表现也不会很干涩。
在使用LoRA时能够比较好地体现画风。
在我LoRA训练得不够好时能够遮瑕。
在训练得足够到位时其自身的画风不会盖过LoRA模型的画风。类似于Windows Defender,必要时提供保护,而在有其他杀毒软件时主动退让。
于是我开始琢磨自行混合Checkpoint。由于我日常训练AnythingV5RE,所以混合时的底模选用的是AnythingV5RE,在此基础上,我向其按各种比例不断混合各个模型,最终得出了CreationMixV1。不能说很不错,但最起码的优点还是有的,至少至少,这个Checkpoint生成的图片里的女孩都在我性癖上。至少至少,它在一定程度上满足了上面的要求,我能够用它生成质量比较不错的模型预览图,也能够在日常中满足我的各种需求。我决定把这个模型发出来,说不定世界上出了我还有人喜欢呢?
The reason for its birth is as follows:
Some artists have few works and iterations, making it difficult to ensure the effectiveness of the LoRA model training. However, too many iterations can lead to overfitting. At this point, the word entries of the LoRA model I trained are usually difficult to grasp.
Some artists' works have unusual poses, especially in R18 works with various positions, and it is difficult to find satisfactory original images after screening. At this time, the effect of the LoRA model I trained will be very poor.
Some artists' works have a lot of details, and normal 2D Checkpoint models are difficult to produce good results. However, 2.5D models usually have rich details.
Some artists' works are relatively three-dimensional, and the effect of 2D Checkpoint models is poor. At this time, 2.5D models usually perform better.
For some artists' works that are relatively flat, the performance of 2.5D models will be very poor, and 2D models will perform relatively better.
I don’t mean anything bad. Mainly speaking of the difficulties I encountered in using various Checkpoints:
DosMix, PerfectWorld, ChikMix, BugerMixSoftPastel, Refslave, NyanMix and others already have their own set of styles, which are obviously not suitable for displaying preview images of the models.
If my LoRA training results are really bad, I won't release them. They can only be made public when they can reflect the style of the artist. However, I cannot guarantee that every result can achieve the desired effect. The effect of AnyLora shocked me. Its performance in expressing the style of the artist is very accurate, which often exposes the shortcomings in my training (which is often caused by my LoRA model not being good enough). In addition, due to the pruning of the model by the experts, they are not very friendly to me in expressing details. My personal level is very limited. The least important thing is that the usual style is not very consistent with my taste. I personally prefer a more delicate style.
YesMix is relatively difficult to perform on some 2.5D artists.
Although CetusMix was a model that I used frequently in the past, it is not suitable for expressing styles.
In my opinion, the preview images of the model with style should be able to achieve the following two points:
It should be relatively close to the style, and reasonably display the effect of the style, so that people can recognize the style of the artist at a glance.
It should be eye-catching. The pictures produced by a simple Checkpoint can reflect the style, but they have no reference value when actually used.
So I started to think, what if there is such a Checkpoint model:
The word entries are complete and the weights of the entries are reasonable.
The generated images are in line with my aesthetics in daily use and can be used as my main Checkpoint.
The facial features are not too three-dimensional, and the character style is neutral, neither too young nor too mature.
The performance is not too stiff without LoRA.
It can reflect the style well when using LoRA.
It can cover up when my LoRA training is not good enough.
When trained sufficiently, its own style will not overshadow the style of the LoRA model. Similar to Windows Defender, it provides protection when necessary, and will take the initiative to retreat when there are other antivirus software installed.
So I started to mix Checkpoints on my own. Since I usually train LoRA by AnythingV5RE, I used AnythingV5RE as the base model for mixing. I continuously mixed various models in different proportions, and finally came up with CreationMixV1. It's not perfect, but at least, the girls in the pictures generated by this Checkpoint are in line with my preferences. At least to some extent, it meets the above requirements. I can use it to generate model preview images with relatively good quality and satisfy my various needs in daily life. I decided to release this model. Maybe there are people in the world who will like it?
--
*注:生成对比图时未改名,ChanterMix即CreationMix;此外,CetusMix应该算2.5D,我的命名存在问题。
*题外话:我在混合时没有加入YesMix和AnyLora,主要是AnythingV5RE和CetusV35,其他的没怎么记。但是出的图在挺多时候和AnyLora意外有点像?
*Note: The name was not changed when generating the comparison image, ChanterMix refers to CreationMix; in addition, CetusMix should be considered as 2.5D, there is an issue with my naming.
*On another note: I did not include YesMix and AnyLora in the blending process, mainly using AnythingV5RE and CetusV35, and I didn't remember the others much. However, in some cases, the images generated are unexpectedly similar to AnyLora?
一般情况: / In general:
1girl
Negative prompt: EasyNegative, sketch, duplicate, ugly, huge eyes, text, logo, monochrome, worst face, (bad and mutated hands:1.3), (worst quality:2.0), (low quality:2.0), (blurry:2.0), horror, geometry, bad_prompt, (bad hands), (missing fingers), multiple limbs, bad anatomy, (interlocked fingers:1.2), Ugly Fingers, (extra digit and hands and fingers and legs and arms:1.4), crown braid, ((2girl)), (deformed fingers:1.2), (long fingers:1.2),succubus wings,horn,succubus horn,succubus hairstyle, (bad-artist-anime), bad-artist, bad hand, too many hair, cat ears, animal ears,
Steps: 30, Sampler: DPM++ 2M Karras, CFG scale: 9.5, Seed: 106059479, Size: 672x1056, Denoising strength: 0.6, Clip skip: 2, Hires upscale: 1.6, Hires steps: 20, Hires upscaler: Latent
Used embeddings: EasyNegative [119b]
图片下载链接 / Image download link (69.7MB):https://o365cn1-my.sharepoint.com/personal/cdn-cn_o365cn1_onmicrosoft_com/_layouts/52/download.aspx?share=EaQWvFCKDtlHiT_kIvcPcVQBr34jziEVu1UfeKGGbDkZsw

这是训练得比较好的模型的测试:/ Here's a test of the better trained model:
1girl, arm_support, bangs, bare_shoulders, black_hair, black_kimono, blunt_bangs, collarbone, floral_print, green_eyes, hair_ribbon, hairband, hime_cut, japanese_clothes, kimono, kimono_pull, long_hair, long_sleeves, looking_at_viewer, medium_breasts,naked_kimono, obi, print_kimono, ribbon, sash, solo, <lora:style_HAPPOBIJIN:1>
Negative prompt: sketch, duplicate, ugly, huge eyes, text, logo, monochrome, worst face, (bad and mutated hands:1.3), (worst quality:2.0), (low quality:2.0), (blurry:2.0), horror, geometry, bad_prompt, (bad hands), (missing fingers), multiple limbs, bad anatomy, (interlocked fingers:1.2), Ugly Fingers, (extra digit and hands and fingers and legs and arms:1.4), crown braid, ((2girl)), (deformed fingers:1.2), (long fingers:1.2),succubus wings,horn,succubus horn,succubus hairstyle, (bad-artist-anime), bad-artist, bad hand,badhandv4,EasyNegative,too many hair
Size: 672x1056, Seed: 413740674, Steps: 30, Sampler: DPM++ 2M Karras, CFG scale: 9.5, Clip skip: 2, Hires steps: 20, Hires upscale: 1.6, Hires upscaler: Latent, Denoising strength: 0.6
图片下载链接 / Image download link (16.0MB):https://o365cn1-my.sharepoint.com/personal/cdn-cn_o365cn1_onmicrosoft_com/_layouts/52/download.aspx?share=Ed1Wyr-L24xOqwqst4n8B8EBYJbI7t41h42HPTNCtp9WYA

这是训练得不那么好的模型的测试:/ Here's a test of the less well-trained model:
1girl, absurdly_long_hair, aqua_eyes, aqua_hair, aqua_necktie, bare_shoulders, black_legwear, black_skirt, boots, detached_sleeves, expressionless, frills, full_body, gradient, gradient_background, grey_background, hair_ornament,headphones, headset, holding, long_hair, looking_at_viewer, miniskirt, necktie, paper, pleated_skirt, ribbon, shirt, shoulder_tattoo, skirt, sleeveless, sleeveless_shirt, solo, standing, thigh_boots, thighhighs, twintails, very_long_hair, white_shirt, zettai_ryouiki <lora:style_Rella:1.2>
Negative prompt: sketch, duplicate, ugly, huge eyes, text, logo, monochrome, worst face, (bad and mutated hands:1.3), (worst quality:2.0), (low quality:2.0), (blurry:2.0), horror, geometry, bad_prompt, (bad hands), (missing fingers), multiple limbs, bad anatomy, (interlocked fingers:1.2), Ugly Fingers, (extra digit and hands and fingers and legs and arms:1.4), crown braid, ((2girl)), (deformed fingers:1.2), (long fingers:1.2),succubus wings,horn,succubus horn,succubus hairstyle, (bad-artist-anime), bad-artist, bad hand,EasyNegative, badhandv4
Steps: 30, Sampler: DPM++ 2M Karras, CFG scale: 9.5, Seed: 1933226217, Size: 672x1056, Denoising strength: 0.68, Clip skip: 2, Hires upscale: 1.6, Hires steps: 23, Hires upscaler: Latent
图片下载链接 / Image download link (16.0MB):https://o365cn1-my.sharepoint.com/personal/cdn-cn_o365cn1_onmicrosoft_com/_layouts/52/download.aspx?share=EbpDz5UI7gJGnA4pdLQYfxkBFwogWaWjmgUgT7PjAmJmdA

--
主要混合:AnythingV5RE(45%+)、CetusMixV35(40%+)
画风类型:2D
模型类别:Checkpoint
模型格式:Safetensors
模型大小:3.97GB
模型精度:float32(全精度,大概)
嵌入VAE模型:否
MD5:2dc9a13aa66ed7d25ccab7d5501dcd03
SHA256:1065c5d2e06464103fe1c85e2ac6fb5aa7d216d4ac1b8811cf91775e29ae318e
-
Main blending models: AnythingV5RE (45%+), CetusMixV35 (40%+)
Style type: 2D
Model category: Checkpoint
Model format: Safetensors
Model size: 3.97GB
Model precision: float32 (approximately)
Embedded VAE model: No
MD5: 2dc9a13aa66ed7d25ccab7d5501dcd03
SHA256: 1065c5d2e06464103fe1c85e2ac6fb5aa7d216d4ac1b8811cf91775e29ae318e

W model you'll know
Selena GomezJenna OrtegaCeleb
This is a merge between Meina's Pastel V3, Fikosofter's Lyriel V1.3 and Pastel-Mix by Andite.
I highly suggest you go try out each of these models yourself, they are all super high quality so you wont be disappointed!
Vae is baked.
Please use Hi-res fix!
Make sure to specify a Hair and eye colour and add (blue eyes, pink hair) in your negative prompt! You will find that every character will have blue eyes and a lot of the times pink hair if you don't.
Share you creations, I would love to see you make with the model!
Meina: https://civitai.com/user/Meina
Fikosofter: https://civitai.com/user/FIKOsofter
Andite: https://civitai.com/user/andite

I use: CLIP 1
No baked in vae, I myself use:
https://huggingface.co/stabilityai/sd-vae-ft-mse-original/tree/main
Feel free to use your own preffered vae!


I recently got into AI and Image Generation and decided to make a model.
It creates anime but is somewhat capable of creating realistic images.
Can be used for nsfw content.
Willing to take feedback :)

Model for Portrait Photography
// Update V5 //
use (best quality, masterpiece:1.2) for high quality image
Sample Prompt :
(best quality, masterpiece:1.2), Woman, Portrait, at night, dark cafe, detailed sky
// Recommend //
Step 20-25
Text Guidance 6-7
DPM 2M Karras
....................................
// Version V4 //
Realistic
Sharpen
Beautiful Face
// Recommend //
Step 30
Text Guidance 7.5
DPM 2M Karras
***Large Image Size for High Quality

This is Slimy's SuperModel. The intent of this merge was to create a higher quality mix with a focus on characters, details, and effects.
The example images are all unmodified and done using text2img with hires fix enabled. The VAE that I used was vae-ft-ema-560000-ema-pruned

Sampler: Euler a / DPM++ 2M Karras
Steps: 20 - 30
CFG scale: 5 - 7
Clip skip: 2
Denoising strength: 0.25 - 0.45
Hires fix: On
Hires upscale: 2
Hires upscaler: R-ESRGAN 4x+ Anime6B / R-ESRGAN 4x+
Negative prompt: paintings, sketches, (worst quality:2), (low quality:2), (normal quality:2), lowres, ((monochrome)), ((grayscale)), bad anatomy
Negative embeddings: EasyNegative, badhandv4

生成BJD娃娃的模型,总体来说很烂,比较失败,只有脸能凑合看,出现身体比例就容易崩,记得填负面tag,不填的话脸也容易崩

We encourage you to share your awesome AI generations.
If you want to support my work, you can buy me a coffee or tea: https://www.buymeacoffee.com/gswan
"Unstable Dissusion was created in response to Stability AI's decision to neuter the 2.0 model."
This model is based on the official unstable_diffusion . Credit to the original developers and donors.
The data was collected by volunteers in the Unstable Diffusion community, and the model was trained by the Unstable Diffusion development team. You can join the community here: https://discord.gg/unstablediffusion
unstablephotorealunstablediffusion
☞(Please read below the Pro Tips & Tricks section for the vae & necessary settings to get the best results!)☜
A hand selected collection of the best of the best, no compromise models to make up this collection!
Specializes in traditional Western Style Comic Characters 2D-2.5D Semi-Realistic, Illustrations & Fantasy Art!
Will do everything from sketch designs, to full comic posters, character concepts, panel layouts, complex scenery, fantasy art of all kinds, sci-fi, retro, etc. The results are endless!
From 2D to Boris Vallejo Paintings and other artists this will do almost everything with a bit of prompt crafting!
It also works with LORAs & EMBEDS without difficulty and generates some very unique and interesting results. (Can't guarantee every LORA will work with it. but many I've tried seem to without issue.)
It's created to be a catch all for this particular medium and I've tested this model for a month exclusively and have been very impressed with its results.
No embedded VAE but this particular vae is required to get the results & examples shown: (The Vae has also been added to the file list)
YOU NEED TO USE THIS VAE!
There is a PRUNED & FULL VERSION
================>🌟WORKS BEST WITH CLIP SKIP 1! 🌟<==============
(seriously use this or you will not get results like the image examples at all.)
I recommend & use the following negatives commonly:
EasyNegative (The all around catch all. Always good in a bind)
badhandv4_anime (absolutely your go to neg for anime / drawn hands)
bad-hands-5 (good for the more realistic images but many times will not work amazingly for just anime. I usually use this and badhands4_anime together)
bad-artist \ bad-artist-anime (I've had good & bad luck with this but sometimes it's great.)
bad_prompt \ bad_prompt_version2 (works very good sometimes)
===========================================================
This is complex mix that I'll share information about how it was made in the near future.
I'm going to take a break for a while as I've been working on this fairly solid for over a month straight! I hope you all enjoy it and show me what you make with this magical model <3
🌟Below (and also other images in the gallery) are examples of the styles you can achieve from the model just by changing the weights on a few simple prompts like: (Comic Style), (Realistic), (Line Art), (Illustration), (Curisscaro), etc. (These image examples w/ prompts are in the gallery for your use & reference.)
MANY examples will be going up in the next few days. So keep your eyes peeled!
=========================================================
A walkthrough on how to setup and use the basics in A1111 to get the results you see:
===========================================================
Blurred eyes, or sometimes warped faces are not that uncommon in SD and sometimes require an inpaint to pull off. Most of my examples are not inpainted. But a few are.
First off when you run txt2img ALWAYS use HIRES FIX! <===
Upscaled: latent (nearest or exact) upscale, or 4x-UltraSharp.
Denoising: 0.35-0.7 denoise (Complete variable - depends on the type and complexity of the image. YMMV! But 0.4-0.55 is a good window.)
Upscale by 1.5-2 but no more than that.
This will get you a pretty good base image to work with.
Afterwards.. You can always send your txt2img picture to inpaint on the bottom right under the result area > select the face or eyes > lower the denoise strength to 0.5-0.57. > make sure your seed is set to random.
masked content = fill / inpaint area = whole picture ====== for faces
masked content = fill / inpaint area = only masked ====== for eyes
With "whole picture" selected for larger inpaint target aka faces (or hands) you may need the denoise to be lower to pick up more of the original image. 0.53-0.56
Now with "only masked" and a smaller target like eyes you get a little more freedom so your denoise can be 0.54-0.57
Run a batch of 4-5 (or more) for the faces.. go through pick the best one.. if you're lucky you got the eyes and face in one go... if not you may need to choose the best face.. send back to inpaint again.. select just the eyes.. and rerun a new batch (changing it to only masked and the settings described above for eyes.)
Finally when you get it all together send to extras:
Resize to 1.5-2
Upscale 1= Nearest
Upscale 2= R-ESERGAN 2x or 4x
But google or get yourself these:
Remacri Upscaler
Lollypop Upscaler
4x_Fatality_Comix_260000_G
4x_NMKD_Superscale-SP_178000_G
(Install these into the proper directory: A1111-Web-UI-Autoinstaller\stable-diffusion-webui\models\ESRGAN and reload a1111.)
Upscaler 2 is what will get you the results you want. You can also drag the upscaler 2 visibility to control the amount of effect each puts on the finished result. (I recommend turning it up 1 but YMMV.)
Ramacri / Lollypop / & Fatality Comix are neck and neck for the best output!
They are all different. One is sharpest, One is more subdued, and one is like a sharp HD.
Each are good for any type of comic / illustration / cell shading / anime.
NMKD_Super is more for semi-realistic to real images and good for scenery. Tends to run sharp so you may have to turn it down a bit.
Each of these is unique and so is their outputs if you want to compare simply change the pull down and run off the various types and contrast / compare all your the finished results.
For the more advanced upscale: Get yourself Ultimate SD Upscale
(click the link for a basic tutorial on how to get it and how to use it.)
Good Luck & Have Fun!
illustrationcomic stylerealisticComic PosterLine Art
The model hashes on Auto1111 should be:
comfyroll_v10.safetensors or Comfyroll_v1_fp16_pruned.safetensors [6535cb6a30]
Comfyroll_v1_fp32_pruned.safetensors [d0188739a3]
comfyroll_v10Anime.safetensors or ComfyrollAnime_v1_fp16_pruned.safetensors [a82cd54e9e]
ComfyrollAnime_v1_fp32_pruned.safetensors [95d81b301b]
Please redownload if they don't match up.
The Comfyroll models were built for use with ComfyUI, but also produce good results on Auto1111. They currently comprises of a merge of 4 checkpoints. A fifth checkpoint may be added following further testing.
The models can produce colorful high contrast images in a variety of illustration styles. A pseudo-HDR look can be easily produced using the template workflows provided for the models.
These checkpoint merges are particuarly good for:
semi-realistic styles (use Comyroll)
stylized anime (use ComyrollAnime)
illustration styles
2.5D
NSFW
ComfyrollReal is a more realistic version and may be released following more testing.
These merges were not designed for creating NSFW and in general do not produce unsafe images unless you deliberately prompt for them. The models are not good for NSFW hardcore.
A collection of workflow templates has been designed for use with these models. The collection includes workflows for anime and illustration styles.
https://civitai.com/models/59806/comfyroll-template-workflows
These templates were used to create the sample illustrations for the models. I have indicated in the comments on each image the template that was used and additional information such as the clip skip, noise masks and lora.
It is also planned to create example prompts for use in Auto1111.
Sampler: dpmpp_2m karras, uni_pc normal
Steps: 10 steps for a contrasty manga-style look and 30+ steps for a smoother look
Clip Skip: both -1 and -2 both work well, -2 provides a good semi-realistic look, -1 is great for anime and illustration styles
Img2Img Denoise: usually between 0.85 to 0.95 (lower values are good for illustration styles)
VAE: vae-ft-mse-840000-ema-pruned (the models do not currently have baked VAE, so you will need a VAE loader node in your workflows)
These models work best when combined with noise masks in Img2Img or ControlNet. Please see the Comfyroll Template Workflows for examples of how to use noise. Recommended noise patterns include white noise, pink noise, dissolve noise and perlin noise.
Hires fix is strongly recommended
Sampler: DPM++ 2M Karras, UniPC,
Steps: 20, Hires 30
Clip Skip: -2
VAE: vae-ft-mse-840000-ema-pruned
Here are some suggested keywords to use in prompts for these models:
Semi-Realistic Style
2.5D, semi-realistic,
highest quality, detailed,
depth of field, natural blur, bokeh, HDR,
Anime Style (ComfyrollAnime)
2D, 2.5D,
anime line-art, illustration,
Illustration Styles
2D, 2.5D,
detailed concept drawing, illustration, line-art, stylized,
Lighting
subsurface scattering, chromatic lighting,
neon lighting, moody lighting, cinematic lighting,
Color
colorized, flat colors, limited color palette
Camera
from-above, from-below, from-side, from-behind,
portrait, cowboy-shot, close-up, long-shot,
ukiyo-e 30% strength
NijiV5style with ComfyrollAnime, 50% strength
Textual inversions:
https://civitai.com/models/7808/easynegative
https://huggingface.co/yesyeahvh/bad-hands-5
Upscalers:
