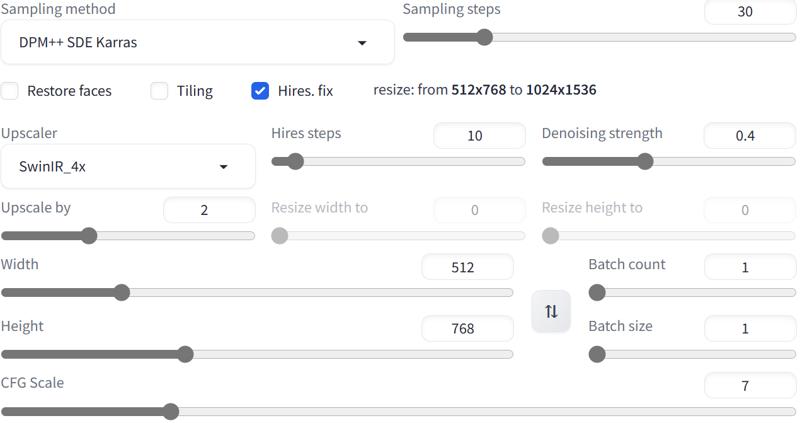
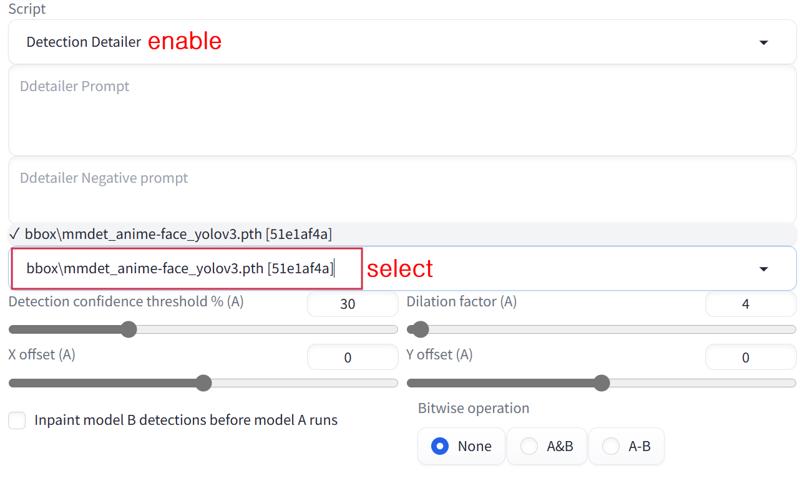
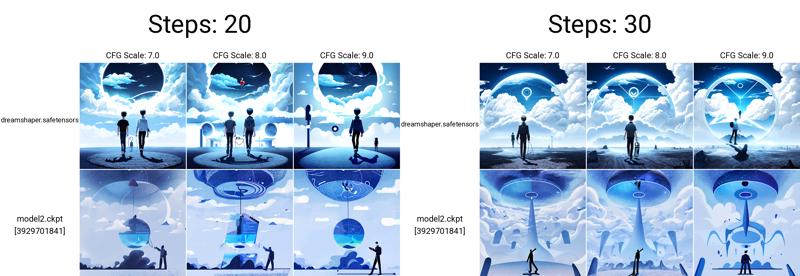
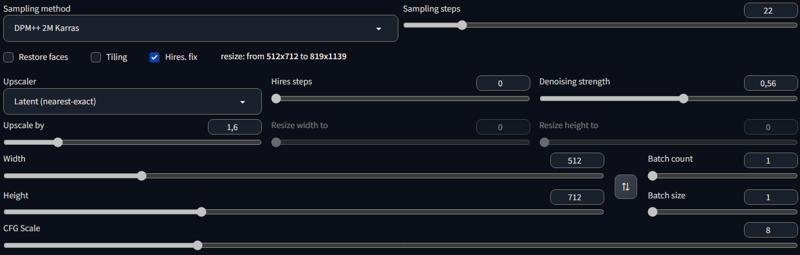
Agartha 👁️🍄🍭🧬🌈
файл на civitaiстраница на civitai🧠🧬Agartha 🧪🍄
Welcome to Agartha .......aka ChadStyle!!!
This mix is inspired from the depths of nostalgia and creativity in all of us. This is a true labor of love. I have mixed this so many times I lost count but have never been happy with it until now. This is by far my favorite style that I have mixed. Ever since the first day I stumbled across Jak’s Creepy Critter’s I was hooked on trying to master a merge that would send each creator on a trip that they will would never forget. I am so happy to finally bring this model to the public. This is by far the cream of the crop for me atm. With this model you can create you wildest childhood dreams and nightmares. Goosebumps was a true passion of mine growing up, so recreating the tales in horrifying HD was a must. I also love creating weird drippy things, so of course FOOD_CRIT was added. Model was inspired by my love for Moist Mix V2 and all things eyegasmic I have found on Civit.You can make some truly bizarre and mind blowing creations with this model so have FUN! Truly, Thank you for stopping by, I really look forward to seeing what you create with this magical merge that I put my heart into!!.. ONE LAST THING….You are amazing!
Fore even more value, If you are interested follow me for the latest updates coming up. https://twitter.com/ultraplayerone
Lyriel 1.6
Babes V2
AiNow
3D Magic Space
Project CryEngine
Chimeramix v2
Aw Portrait
Neurogen 1.1
The Great Fault 1.1
Goosebumps Cover Art by Tim Jacobus
A-Zoyva Ultra photoreal
RoseRenderedMix
Animatrix V2
526Mix-Anime+Animated
526 Cusp Of Serenity
ColorfulSurrealismAI
Artificial Journey
Sentinel Diffusion
Slimy’s Supermodel V2
Lexartdiffuzex
Rev Animated 1.2.2
Xeno Art style V4.5 (2x)
Jak’sCreepyCritters 768px (Food_crit)
Color Fusion
Fruit Fusion
Fever Dream
Holographic model (2x)
Rainbowpatch 1.2
Eris
JimEidomode
DucHaiten-StyleLikeMe
Orusium
Darkful
NeverEndingDream
Dreamshaper V5
MoistMix V2
StyleJourney
DucHaitenDarkside V4
Halcyon
Artius
WyvernMixV8
Colorful V3
Juggernaut V1.7
Odyssey
RmadaV8ColdVae
Mechamix
*If you want to create more appealing faces for humans I suggest using "(comedone, skin cancer, psoriasis, eczema, herpes)” it in your negative prompt.
If you are creating creatures or odd things, my suggestion is to leaving off “(comedone, skin cancer, psoriasis, eczema, herpes)”. (NOTE:This is not my negative, i found it on someone else’s post.) The ai likes to NOT give you goosebump or creepy art if you use that in the negative prompt while focusing on that type of image.
Another trick I have learned is trying things like “(LESS_THAN_GREG_RUTKOWSKI)” in the negative prompt, it makes a DRAMATIC change in your image… like mind blowing sometimes. (NOTE: THIS part is my idea, one day i just said fuck it, im putting alot of this postive stuff in the negative prompt but wording it “LESS_THAN” format and BOOM!!! ) I look forward to seeing what you try in your negative prompt. If you get a pokemon that is deformed for example , try (DEFORMED_POKEMON:1.3) in your negative prompt that worked for me to remove extra pikachu ears and arms. This is experimental stuff so please don’t hold me to it, just remember to have fun.
GOOSEBUMPS ART BY TIM JACOBUSRAINBOWPATCHFOOD_CRITTK-CHARTK-ENVBRTDRPPLIQUID SPLASHPAPERCUTPORCELAIN DOLLartificial-journey styleSURREALISMCOLORFULSURREALISMAICARBONDUOCHROMEHOLOGRAPHIC in OliDisco styleFLAT COLORFLAT ILLUSTRATIONVECTORSTYLEMECHA