Crescent Sun
файл на civitaiстраница на civitaiSHA256: E174FBF8284A299FFF6A1F99276D5CB0BE7302C317EA9B4A8B4739DEDC1A9420
Megan is a sexy co worker with big tits and a round ass. she normally wears overalls
bimboslutmore simple,
more easy!

new model merged.
nsfw possible.
positive -
RAW, 1girl, colorful, (masterpiece, best quality), {1$$cowboy shot|upper body},
(detailed skin:1.3, detailed face:1.3), dslr, realistic, {waving| arms behind head}, looking at viewer,
sharp focus, delicate, (korean beauty, korean mixed), (mature female:1.2),
(Glossy skin + Shiny skin:1.4), (sweaty:1.1),
(big breasts:1.2, thick thighs:1.1, narrow :1.1),
(black_hair, long hair, straight hair:1.3), (big_eyes, brown_eyes), red_eyeshadow, long_eyelashes, red lips,
eyes_smile, stud earrings,
(holographic iridescent metallic black latex swimsuit:1.4),
beach, day, sunlight,
negative -
(worst quality:1.4, low quality:1.4), (normal_quiality:1.4), (loli, child, infant, baby:1.3), ((muscular)), (mouth mask:1.3), wrong_face, topless, bottomless, facepaint, mouth mask, sunglasses, glasses,
hat, tattoo, extra arms, extra digits, multiple girls, multiple views, indoors,

The effect of this model is good, and the styles are quite diverse. I haven't had time to try more styles. If there are interesting pictures, I can show them.
这个模型的效果不错,风格比较多样化,还没有来得及尝试更多种风格,如果有有趣的图片可以展示出来。
用到的采样器https://civitai.com/models/35966/dpm-2m-alt-karras-sampler

HF: https://huggingface.co/OedoSoldier/KawaiiMix
This model is trained on ~100 selected images generated by Nijijourney V5 Cute.
VAE: Orangemix / Anything V4.5 / NAI
Sampler: DPM++ 2M Karras
Sampling steps: 20
Negative embedding: EasyNegative、badhandv4
Highres fix is also recommened


more easy,
more simple

Technically more like V10 but its renamed as V3 to keep in line with my previous versions.
This is a merge of many many checkpoints , including the few dreambooth models i created myself
All credit goes to the other creators in helping me create this version.
It can and will create both SFW and NSFW images with the correct prompts
V4.0 is live


wait

Explore your imagination!
Artuis is a versatile and flexible model, it allows you to generate crisp, high-resolution images:
- Realistic portraits
- NSFW
- Stylized Art
- Logos
- Game assets
- Texture
- People, animals, food photos and more
- Product concept
- Any genre: Realistic, Fantasy, Sci-Fi, Cyberpunk, Anime and more
This model is biild with Noise Offset, so it tends to darker images, keep this in mind when making prompts
This is SD 1.5 based model, also I have SD 2.1 based version: https://civitai.com/models/27739/artius-v21
This model is very NSFW sensitive, so be careful :-)
If you liked my model, please leave a review, it helps other users to find this model and see its features!
The model works best with the following samplers:
Euler a
DPM2
DPM++ 2M Karras
Optimal settings:
Clip skip 1
DPM++ 2M Karras
25 Steps
CFG Scale 5-6
Resolution 512 or 768
The model is prompt and NSFW sensitive, so it depends on your imagination.
I've generated some demo images, you can study the prompt and make your own based on them.
To make unique faces, mix faces that the model knows: [person1 : person2 : 0.5]

Big update of DucHaitenAIart, v4 is able to receive more diverse, more detailed prompts with gorgeous colors and more realistic shadows. The image has the breath of 3D anime, but the material is much more realistic.
For those of you who don't have a pc or a weak computer, you can consider using my model via sinkin and mage website using the link below:
please support me by becoming a patron:
*****
All sample images only use text to image, no editing, no image to image, no restore face no highres fix no extras.
DPM++ 2S a Karras cfg 11
negative prompt:
illustration, painting, cartoons, sketch, (worst quality:2), (low quality:2), (normal quality:2), lowres, bad anatomy, bad hands, ((monochrome)), ((grayscale)), collapsed eyeshadow, multiple eyeblows, vaginas in breasts, (cropped), oversaturated, extra limb, missing limbs, deformed hands, long neck, long body, imperfect, (bad hands), signature, watermark, username, artist name, conjoined fingers, deformed fingers, ugly eyes, imperfect eyes, skewed eyes, unnatural face, unnatural body, error

more easy,
more simple

More simple
More easy

THIS IS A MERGE OF 30 DIFFERENT MODELS + MY OWN VTUBER LORA! TO GENERATE A VTUBER USE THE KEYWORDS "vtubermodel , full body , white background"
Hey all i hope you enjoy this model as much as i do! it has a wide range of capebiliteis including nsfw but mostly production quality stuff! i made sure merge in a lot of realism models in there to acheive maximum results on hand accuracy and details ^^

This model is mix of Kenshi by Luna and AnythingV3 by Yuno779.
It was my first model merge, and I was quite suprised. It does consistenly great and works pretty well with NAI-based LoRAs.
Also you can check out AIBooru, a website on which you can share your AI-generated works with others.
======================================================================
Best VAE: vae-ft-mse-840000-ema-pruned (highres fix or sd upscaling is desirable to use)
Best upscaler: 4x-UltraSharp
Textual Inversions I recommend to use: EasyNegative | bad-artist-anime | ng_deepnegative_v1_75t | bad-hands-5

Fraufembot
ISO mix now available v2.11!!!
Read about this version to find out about the changes.
This mix is made from other models based on anime, realism styles that ended up resulting in something in between render 3d and art.
The model is very flexible, capable of both NSFW and fully censored work. Everything is limited by your imagination. You can get good results on short promt as well as on extensive.
Who would be suited for this model
- NSFW artists
- Lovers
- Designers
Comfortable sampler DPM++ 2M Karras, steps 30 to 50, SFG 5.5 to 9.5, for best results use HiRes fix upscaler R-ESRGAN 4x+ or 4X_Valar_v1 both work well
Model does not require vae since it is already built in, good results with CLIP 1-3 depending on your request.
Comfortable with many LORAs at 0.5-1 weight
Enjoy, write me if you have any mistakes

简单来说就是把常用的模型和lora进行了融合(因为调用起来实在太麻烦)于是就现在这个模型,玩的开心,底模是冬月L
Machine translation:
Simply put, it's a fusion of commonly used models and Lora (because it's too cumbersome to call), so let's have a good time with this model now. The bottom model is Winter Moon L

This model uses the core of the Defacta 3rd series, but has been largely converted to a realistic model.
It supports a new expression that combines anime-like expressions with Japanese appearance.

If you support me, I will make many AI male models and try to improve them more beautifully.
***
PastelBoys 2D ver.3 has a brighter color and a more delicate background.
However, the new version has difficulty in creating men other than teenagers and twenties guy. If you want to create a child or a middle-aged man, I recommend you to use ver.2.
Recommended Settings
Sampling method : Eular a / DPM++ SDE Karras
Clip skip : 1~2
Hires.fix upscaler : R-ESRGAN 4x+Anime6B
CFG Scale : 7~9
VAE : vae-ft-mse-840000-ema-pruned / kl-f8-anime2

It does the big booba lol.
I made this on a whim trying to replicate someone else's generation but this is actually fairly decent. It's pretty good at doing fantasy and cultural stuff in a sort of illustrative, not quite cartoon but also not quite realistic style. IME you're best using this either for full body portraits or epic fantasy scenes.
HuggingFace for recipe.
I dunno lol. I mostly just stole prompts from ReV Animated and UmiAI fantasy mix. It seems to do both booru style tags and prose prompts pretty well. Try mixing and matching. It's surprisingly responsive to prompts so I figure that probably all the merging has fed it a bunch of weights and normalized their bias.
As to the upscaler, any GAN type upscaler will work fine. Latent sometimes works but is more finicky than not.

团圆已经过了。还想吃一点汤圆吗?
I tried out Dark Sushi 大颗寿司Mix (aka Dark Souls mix because it's pronounced dàkēshòusī in Chinese lol) and thought it was fantastic. That's based on Five Nuts Mooncake 五仁月饼Mix which is in turn a mix of Three Delicacy Wonton (三餡馄饨Mix) (Obligatory self-plug), ReV Animated, and 啥玩意完犊子(大概是一种古早画风)- old fish (I don't understand this name tbh). That gave me an idea.
I have a model based on ReV Animated. Why not try mixing it with Wonton? Hence, 汤圆Mix. SomethingV3B sweet and sticky yet wet and soupy at the same time. 水水汤汤甜甜黏黏,这就是汤圆!
As far comparisons to Wonton go, TangyuanMix is SanXianWonton = lines + color - watercolor. If you just want Wonton with brighter more vivid colors, Ashen's ColorBox color-enhancement of WontonV1 is still the way to go, but if you're looking for something that captures more of WontonV2's soft linework while still adding color (just less vivid) this is a good middle ground.
Use it however you would like. It is a generalized model. I recommend trying to prompt for beautiful backgrounds with it, since it has a lot of silicon and dpep4 lineage, it should be good at scenery. Theoretically.
@ayyyy22002 我终于用了这个汤圆的名字。你满意吗?

Merge of Rev Animated and Orange 50/50 mix with some additional training on video game characters. Will be updated often and pruned as much as possible (goal is 2GB).
WARNING: This model horny, fr fr.
Great for anime/games/nsfw and portraits.
Works great for 512x768 and obviously 512x512.
Start prompts with: (masterpiece:1.1, best quality)

我非常喜欢这个风格的模型,但是很多我想要的效果无法表达出来。我花了一点时间去处理了一下这个模型,使其效果得到了一定的提升。
I like this style of model very much, but many of the effects I want can not be expressed. I spent a bit of time working with the model to improve it.
模型无需外挂VAE
VAE does not need to be VAE externally applied to the model。
不建议继续进行训练
Do not recommend for Fine-tuning.
请不要添加“masterpiece”等起手式,除非画面出现各种问题
Please do not add "masterpiece" or other prompt words
CFG可以推荐设置在3~30之间
CFG can be set between 3 and 30, AI painting has infinite possibilities


;3

Merged the same lora as Pastel-mix ,but different main.ckpt,which make it pastel but lines.
Recommend to use Hires.fix and control net.
3/20
It is actually a limited model,which needs to mix with a basic model .
New uploads are the examples.
Everyone is welcome to try.
The initial one is my favourite.
More:

JDZ Beta1 - 22 April 2023
Beta1 is released for testing and evaluation. While convergence was reached, there are 230 styles/concepts contained within. This was trained on my original datasets used to create many CKPT / LORA already released on Civit. The Training Data contains combined instructions on making the most from this new versatile model format.
UPDATE - added new "combined-instructions.zip" now includes Instructions.txt and wildcards.zip. Wildcards are now included for use with Dynamic prompts.
JDZ-CaptionList.txt - ~5000 Example prompts used in captioning the 230 sets
JDZ-StyleTriggers.txt - ~230 "Trigger words" used for each style
JDZenkai-GenPrompts2200.txt - ~4200 "GPT2 Generated Prompts" trained on the Caption List
(Above pictured) Wildcard files now included
Future releases will be trained to Epoch 40 (~200,000 steps)
The Beta1 model is currently trained to Epoch 19 (~97000 steps.
There are many ways to use this model as it contained all my CKPT styles in one model.
You do not need to use Triggers and can prompt normally.
You can prompt using words listed in DJZ-Styletriggers.txt to anchor to a specific style, or use multiple triggers with attention weighting to control the output.
You can use one or more prompts as shown in the DJZ-CaptionList.txt.
You can use the DJZ-CaptionList.txt and/or JDZenkai-GenPrompts2200.txt as a wildcard with Dynamic Prompts, simply place it into the /wildcards/ folder and rename it to your choosing.
I trained a GPT2 Generator which created many variations on the Example Prompts, an example of these are the JDZenkai-GenPrompts2200.txt
This is an ongoing project so expect a LORA version next. It will take some time to create the LORA version due to a difference in the captioning. This is trained using a Parallel Dreambooth Method which prevents concept/style bleeding, but you can still mix by interpolating trained terms/triggers in the prompt.
TLDR there is a missing comma, can you find it?

I merged various things to create the model I wanted.
There is no pathology to merge for the first time.
This is the recommended prom I use. Use it as a reference to create a variety of drawings.
●Positve Prompt :
Fixed Prompt - (masterpiece, best quality:1.3), highres, 4K
Style - realistic, realistic_texture
background - realistic_background
Subject - 1girl, solo
View -
Appearance - (shiny skin:1.2)
Outfit -
Pose -
Details - caustics, cinematic_lighting
Effects -
●Negative Prompt :
(worst quality, low quality:1.4), (odd eyes:1.2), multiple views, lowres, bad anatomy, bad hands, text, error, missing fingers, extra digit, fewer digits, cropped, worst quality, low quality, normal quality, jpeg artifacts, signature, watermark, username, blurry, artist name

shiny_skin
this is a merge of mdjrny-v4 , deepSpaceDiffusion and chilloutmix_NiPrunedFp32Fix

QQ交流群: 704574483
模型仅作为科研兴趣交流使用,如有侵权请联系删除,谢谢!
获得原作者的同意 水一个模型 majic 我把胶片风女孩lora的画风融进来了 哈哈

This is a model related to the "Picture of the Week" contest on Stable Diffusion discord.
This version is trained on dedicated tokens per user, and doesn't work like you may be used to.
It will be included with more usable tokens in the next update of SDArt : Complete Edition.
I try to make a model out of all the submissions, for people to continue enjoy the theme after the event, and see a little of their designs in other people's creations. The token stays "SDArt" and I balance the learning on the low side, so that it doesn't just replicate creations.
The pictures were tagged using the token "SDArt", and an arbitrary token given to the user that submitted it.
The dataset is available below and is composed of 36 pictures.
Encapsulated
What if the world was in the palm of your hands? Condensed, contained, and captured within a simple sphere for all to see?
Create your own world encapsulated within an orb, sphere, container etc. This can be any type of world or landscape you can imagine, but it must be confined within the boundaries of the orb.
Bring your miniature world to life. Big things come in small packages!
A world made of crystals and moss? A lush forest landscape? An upside-down world? A world made of instruments? A world made of tangled wires? Be creative! Be uniquely you!
SDArt
bnp
aten
fcu
cous
aved
arum
omd
kuro
asot
psst
buon
utm
vaw
mss
guin
mgt
crit
isch
phol
vedi
dds
acu
pte
oxi
rean
reba
reem
revs
rith
rmb
rolf
ront
rps
rsc
gare
shld
SDArt
A spin off from Level4. Built to produce high quality photos. Sometimes photos will come out as uncanny as they are on the edge of realism.

CharHelper_Fine_Tuned_V2 has been trained with SD 2.1 as a base at 768x768 resolution as an update to the previous version. It has additional training on anthropomorphism, dinosaurs, reptiles, animals, aquatic creatures, ninjas, wrestlers, food, diners, gardens, and fairgrounds.
Disclaimer:
Some of the sample images used the Dynamic Thresholding and/or Unprompted Extensions. Civitai did not have a place for it with their template so for more info, check the model card on HuggingFace.
The CFG Scale is much less sensitive in this version and can achieve good results between 4 and 9.
I recommend using the Dynamic Thresholding Extension for this model. It becomes much more coherent when it is enabled with the following settings:
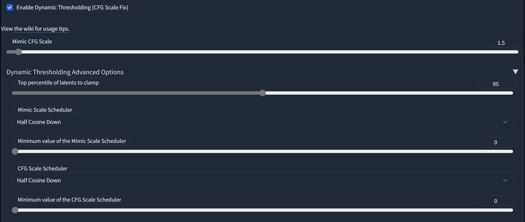
This model also can benefit from the Unprompted Extension's zoom_enhance tool as it likes to output longer range images.
Use Auto for the vae in settings. If you are using a vae based on a SDv1.5 model, you may not get the best results.
Prompts work better when using complete sentences vs the SDv1.x "8k, intricate, etc." type of format.
Keywords are not necessary but I've kept the options for them open. Play around with mixing them up for interesting outputs. They work best with the Prompt Editing Feature which let's the generation focus on the keywords for the first 20% and then can be removed before the image gets too chaotic or vice versa. Using Prompt Editing for artist names as well has had good results.
Keywords:
Character Styles: CHV3CWrestler, CHV3CReptile, CHV3CAnimal, CHV3CNinja, CHV3CAnthro, CHV3CDino, CHV3CFoodPorn, CHV3CDeepSea, CHV3CBigChief, CHV3CBoxer, CHV3CUrban, CHV3COrc, CHV3CGanesh, CHV3CGolem,CHV3CCyberpunk, CHV3CSamurai, CHV3CRobot, CHV3CZombie, CHV3CBird, CHV3MDragon, CHV3CKnight, CHV3CWizard, CHV3CBarb, CHV3CVehicle, CHV3CTroll, CHV3CReaper, CHV3CRogue, CHV3CAlien
Scenery/Styles: CHV3SDiner, CHV3SGarden, CHV3SFair, CHV3SUrban, CHV3SEldritch, CHV3SLighthouse, CHV3SCute, CHV3SMacro, CHV3SSciFi, CHV3SWorld
Fine-Tuned V1:
Introduction:
This model was trained from the ground up using Stable Tuner's fine-tuning method and utilizing contrast fix for darker darks and bolder colors. The Dataset contains 4900 images trained to 35 epochs.
File Name is CharHelper Fine-Tuned.safetensors. Do not forget to download the yaml file and place it in the same directory.
Usage:
Because of the nature of the fine-tuning method, this model is sensitive with the CFG Scale. Photorealism tends to like a LOW CFG Scale. Best result can be found between 3 and 7. Some subjects that are complex like robots like a higher dfg, while photorealism is mostly achieved with a CFG Scale of 3 or 4.
Use Auto for the vae in settings. If you are using a vae based on a SDv1.5 model, you may not get the best results.
CharHelper Fined-Tuned was trained all at once which means the keywords all have more power to them than the previous CharHelper models. CharHelper Fine-Tuned doesn't need keywords but includes them and they can be mixed and matched together in order to acheive a multitude of different styles. Some Keywords were changed slightly from the last version.
Keywords:
Character Styles: CHV3CBigChief, CHV3CBoxer, CHV3CUrban, CHV3COrc, CHV3CGanesh, CHV3CGolem,CHV3CCyberpunk, CHV3CSamurai, CHV3CRobot, CHV3CZombie, CHV3CBird, CHV3MDragon, CHV3CKnight, CHV3CWizard, CHV3CBarb, CHV3CVehicle, CHV3CTroll, CHV3CReaper, CHV3CRogue, CHV3CAlien
Scenery/Styles: CHV3SDark, CHV3SUrban, CHV3SEldritch, CHV3SLighthouse, CHV3SCute, CHV3SMacro, CHV3SSciFi, CHV3SWorld
V4:
File Name is CharHelperV4.safetensors
CharHelper V4 is a merge of CharHelper V3 and a newly trained model. This update is to provide a base for future updates. All older keywords from CharHelper V3 will still work.
Training subjects on this model are Aliens, Zombies, Birds, Cute styling, Lighthouses, and Macro Photography. Mix and match the styles and keywords to push the model further.
Use Auto for the vae in settings. If you are using a vae based on a SDv1.5 model, you may not get the best results.
This model has multiple keywords that can be mixed and matched together in order to acheive a multitude of different styles. However, keywords aren't necessarily needed but can help with styling.
Keywords:
Character Styles: CHV3CZombie, CHV3CAlien, CHV3CBird
Scenery/Styles: CHV3SLighthouse, CHV3SCute, CHV3SMacro
V3:
File Name is CharHelperV3.ckpt
Completely retrained from the begining in a fundamentally different process from CharHelper V1 and 2. This new model is much more diverse in range and can output some amazing results.
It was trained on multiple subjects and styles including buildings, vehicles, and landscapes as well.
Usage:
Use Auto for the vae in settings. If you are using a vae based on a SDv1.5 model, you may not get the best results.
This model has multiple keywords that can be mixed and matched together in order to acheive a multitude of different styles. However, keywords aren't necessarily needed but can help with styling.
Keywords:
Character Styles: CHV3CKnight, CHV3CWizard, CHV3CBarb, CHV3MTroll, CHV3MDeath, CHV3CRogue, CHV3CCyberpunk, CHV3CSamurai, CHV3CRobot
Scenery/Landscapes: CHV3SWorld, CHV3SSciFi
WIPs (needs fine-tuning, but try it out): CHV3MDragon, CHV3CVehicle
Example Prompt:
Mix & Match "CHV3CCyberpunk.grim reaper"
A realistic detail of a mid-range, full-torso, waist-up character portrait of a (CHV3CCyberpunk.grim reaper) costume with beautiful artistic scenery in the background, trending on artstation, 8k, hyper detailed, artstation, concept art, hyper realism, ultra-real, digital painting, cinematic, art award, highly detailed, attractive face, professional hands, professional anatomy, (2 arms, 2 hands)
Negative prompt: NegLowRes-2400, NegMutation-500, amateur, ((extra limbs)), ((extra barrel)), ((b&w)), ((close-up)), (((duplicate))), ((mutilated)), extra fingers, mutated hands, (((deformed))), blurry, (((bad proportions))), ((extra limbs)), cloned face, out of frame, extra limbs, gross proportions, (malformed limbs), ((missing arms)), ((missing legs)), (((extra arms))), (((extra legs))), mutated hands, (fused fingers), (too many fingers), (((long neck))), (tripod), (tube), ugly, tiling, poorly drawn hands, poorly drawn feet, poorly drawn face, out of frame, mutation, mutated, extra limbs, extra legs, extra arms, disfigured, deformed, cross-eye, body out of frame, blurry, bad art, bad anatomy, (umbrella), weapon, sword, dagger, katana, cropped head
Steps: 10, Sampler: DPM++ SDE Karras, CFG scale: 9, Seed: 1840075390, Size: 768x896, Model hash: cba4df56, ENSD: 3
V2:
Trained for an additional 5000 steps. Result will be much more stable and major improvement over V1. Don't forget to add the yaml file into your models directory.
V2 checkpoint filename is CharHelper_v2_ SDv2_1_768_step_8500.ckpt
Usage:
This model tends to like the higher CFG scale range. 7-15 will bring good results. Images come out well if they are 756X756 resolution size and up.
A good prompt to start with is:
(a cyberpunk rogue), charhelper, ((close up)) portrait, digital painting, artwork by leonardo davinci, high detail, professional, masterpiece, anime, stylized, face, facial expression, inkpunk, professional anatomy, professional hands, anatomically correct, colorful
Negative: ((bad hands)), disfigured, distorted face, mutated, malformed, bad anatomy, mutated feet, bad feet, poorly drawn, ((odd proportions)), noise, blur, missing fingers, missing limbs, long torso, ((ugly)), text, logo, over-exposed, over-saturated, ((bad anatomy)), over-exposed, ((over-saturated)), (((weapon))), long neck, black & white, ((glowing eyes))
Just substitute what's in the begining parenthesis with your subject. You can also substitute "((close up))" with "((mid range))" as well. These worked best for me, but I'm excited to see what everyone else can do with it.
CHV3CWrestlerCHV3CReptileCHV3CAnimalCHV3CNinjaCHV3CAnthroCHV3CDinoCHV3CFoodPornCHV3CDeepSeaCHV3CBigChiefCHV3CBoxerCHV3CUrbanCHV3COrcCHV3CGaneshCHV3CGolemCHV3CCyberpunkCHV3CSamuraiCHV3CRobotCHV3CZombieCHV3CBirdCHV3MDragonCHV3CKnightCHV3CWizardCHV3CBarbCHV3CVehicleCHV3CTrollCHV3CReaperCHV3CRogueCHV3CAlienCHV3SDinerCHV3SGardenCHV3SFairCHV3SUrbanCHV3SEldritchCHV3SLighthouseCHV3SCuteCHV3SMacroCHV3SSciFiCHV3SWorld
Mix Realistic Model
Lora
vae-ft-mse-840000-ema-pruned

推荐参数
Recommended Parameters:
Sampler: DPM++ 2M Karras alt Karras or DPM++ SDE Karras
Steps: 20~40
Hires upscaler:4x-UltraSharp
Hires upscale: 2
Hires steps: 15
Denoising strength: 0.2~0.5
CFG scale: 6-8
clip skip 2

This model is a merge of Anything V3 with Easter e9 (70/30), with SnackbarGeneral e11 (60/40). it is a generalist furry merge i made some time ago. i still use this merge as an admix for other merges, as it has good variety and can reach high specitivity with prompts. it is limited in the maximum quality it can reach though by being based on older models.
I upload it for completion sake, as i reference it in other models.
as a standalone model it can produce decent outcomes, but also a lot of low quality or mangled images.
as a low percentage admix to a merge it can act as a wildcard or tuner.

This model is a merge of Lodestones "Fluffyrock" model (fluffyrock-576-704-832-960-1088-lion-low-lr-e17) with a 16% addition of the AnyEasterSnack merged model. It is geared towards broadening the styles and Results possible in the very good Fluffyrock model without losing too much of said quality.
Its an alternative to the model that includes Yiffy e18 as well and has different strengths and weaknesses.
I am not Lodestone and would advice all to check his original work at https://huggingface.co/lodestones or on the Furry Diffusion Discord https://discord.com/invite/JKS7UttReS

Check the version description below (bottom right) for more info and add a ❤️ to receive future updates.
Do you like what I do? Consider supporting me on Patreon 🅿️ to get exclusive tips and tutorials, or feel free to buy me a coffee ☕
Live demo available on HuggingFace (CPU is slow but free).
Available on the following websites with GPU acceleration:
MY MODELS WILL ALWAYS BE FREE.
NOTES
Version 5 is the best at photorealism and has noise offset.
Version 4 is much better with anime (can do them with no LoRA) and booru tags. IT might be harder to control if you're used to caption style, so you might still want to use version 3.31.
V4 is also better with eyes at lower resolutions. Overall is like a "fix" of V3 and shouldn't be too much different. Stay tuned for V5!
Results of version 3.32 "clip fix" will vary from the examples (produced on 3.31, which I personally prefer).
I get no money from any generative service, but you can buy me a coffee.
You should use 3.32 for mixing, so the clip error doesn't spread.
Inpainting models are only for inpaint and outpaint, not txt2img or mixing.
After a lot of tests I'm finally releasing my mix. This started as a model to make good portraits that do not look like cg or photos with heavy filters, but more like actual paintings. The result is a model capable of doing portraits like I wanted, but also great backgrounds and anime-style characters. Below you can find some suggestions, including LoRA networks to make anime style images.
I hope you'll enjoy it as much as I do.
Diffuser weights (courtesy of /u/Different-Bet-1686):
https://huggingface.co/Lykon/DreamShaper
Official HF repository: https://huggingface.co/Lykon/DreamShaper
Suggested settings:
- I had CLIP skip 2 on some pics (all of them for version 4)
- I had ENSD: 31337 for basically all of them
- All of them had highres.fix or img2img at higher resolution.
- I don't use restore faces, as it washes out the painting effect
- Version 4 requires no LoRA for anime style. For version 3 I suggest to use one of these LoRA networks at 0.35 weight:
-- https://civitai.com/models/4219 (the girls with glasses or if it says wanostyle)
-- https://huggingface.co/closertodeath/dpepmkmp/blob/main/last.pt (if it says mksk style)
-- https://civitai.com/models/4982/anime-screencap-style-lora (not used for any example but works great)
NOTE: if you find that the prompts below look "familiar" it's because I've taken them from other reviews and models here, to basically compare my model to other examples. Credits to the original authors. Thanks for the benchmark.

Merge based on the following models:
Recommended Settings:
Sampling Method
DPM++ SDE Karras
Euler a
DPM++ 2S a
DPM2 a Karras
Sampling Steps
40 (20 to 60)
CFG Scale
7 (6 to 9)
Clip Skip
1
VAE
None (Baked)
Any questions or suggestions you can contact me through Discord: Cisney Gassai#5108

While the results can be good, its a bit of a hard-headed model...I'm still learning.
Will produce almost anything (as long as it's anime) without too much of a prompt, see Notes below.
This is my first merge, I've sort of lost the recipe at this point but it's using mostly
Highly recommended to use EasyNegative
The model tends to make women unless specified otherwise in your prompts
I'm still new to this so I'll add more details on here as I get feedback from the community.
