IMPORTANT MATTERS(重要事项)
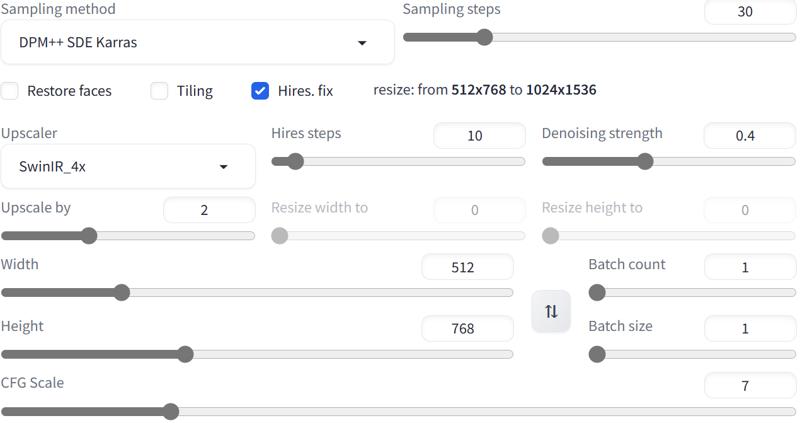
Highres-Fix is A Must! Highres-Fix: 2x, denoising:0.4-0.5 or 1.5x, denoising:0.5-0.65. (一定要做高清修复! 高清修复: 2倍, 重绘幅度:0.4-0.5 或 1.5倍, 重绘幅度:0.5-0.65)
Make Sure you are in the right CLIP if you want to replicate my job, some themes are CLIP=1,while others are CLIP=2.Suggest download the image and put it into PNG info to check the setting (如果想要复现,确保CLIP值要对! CLIP1和CLIP2要对!建议把图下下来然后放到PNG信息里面去查设置)
Most Prompts in Previous Version of GhostMix can produce similiar result in New Version of GhostMix (之前用的大多数Prompts在新版本也可以生成相似的结果)
All images I posted did not use Lora & Controlnet. (所有图片没有用Lora和Controlnet)
Textual Inversion&VAE: ng_deepnegative_v1_75t and easynegative ,don't use Bad-Hand V4 & V5!(用 ng_deepnegative_v1_75t和easynegative,别用BadHandV4,V5)
Sampler Suggest : DPM++ series , Steps: 20-30, CFG:5-7(7 is best)(采样方法建议 DPM++系列 , 步数20-30, CFG:5-7(7最好) )
Suggest resolution: 512,768! mechanical girl theme is very sensitive to the resolution, not suggest make the aspect ratio too low.(建议分辨率:512,768! 机械少女主题对分辨率设置非常敏感,不建议设太低的宽高比)
If you want to support me, please buy me a coffee : https://ko-fi.com/ghostshell
如果想支持我,可以买杯咖啡给我:https://ko-fi.com/ghostshell
2023.5.21 GhostMix-V2.0 (fp16 pruned ver replaced)
UPDATE DETAIL(中文更新说明在下面)
Hello everyone, this is Ghost_Shell, the creator. The GhostMix-V2.0 significantly improves the realism of faces and also greatly increases the good image rate. In my tests at 512,768 resolution, the good image rate of the Prompts I used before was above 50%. It is more user-friendly. During making the GhostMix-V2.0, I adjusted 47 versions of the model and finally chose one of them.
大家好,这里是作者Ghost_Shell。这次GhostMix-V2.0大幅提升了脸的真实性,也大幅提升了良图率,在我测的512,768分辨率之下,之前用的Prompts良图率都在50%以上,对用户更加友好。这次在测试中一共调了47个版本的模型,最终选了一个。
Other Words I want to say(题外话):
To be honest, this may be the last version of GhostMix.On one hand, it is really inefficient to use 3060ti to make models. In the past two weeks, I have almost no free time except for making models and testing them. On the other hand, I temporarily feel that this model is almost at its limit and the space for improvement is really not high. I hope you like it. If you like the model, I hope you can post your images to Civitai. Many of the prompts I tested for GhostMix-V2.0 are from your posts, which is really important for me to test the model. If you can give it a 5-star rating, that would be great. If you are willing to support my work, please click: https://ko-fi.com/ghostshell. My goal is to buy a 4070 and work more efficiently on making models. Using a 3060ti to make models is really inefficient and it basically cannot be used to test high resolution images.
说实话,这可能是GhostMix的最后一个模型,一方面3060ti去做模型真的效率太低了…最近两个星期基本没有空闲时间,除了做模型,就是测模型。另外一方面,我暂时觉得这个模型近乎极限,能提升的空间确实不高了,希望大家喜欢。如果大家喜欢模型,希望大家能post自己的作品到Civitai,这次测试的很多Prompts就是从你们post里面来的,这对我测试模型真的很关键,如果能5星评价就更好。如果愿意支持我的工作,请点击:https://ko-fi.com/ghostshell。 我的目标就希望能换一块4070,更高效的去做模型,3060ti真的测模型效率太低了,而且基本没法测更高分辨率的图片。

2023.5.1 GhostMix-V1.2 (fp16 version uploaded)
UPDATE DETAIL(中文更新说明在下面)
THIS IS NOT A 3D MODEL! THIS IS NOT A 3D MODEL! THIS IS NOT A 3D MODEL!
If you like my model,please give me 5 Stars ,it will encourage me a lot. Thanks!
Color Problem :Check VAE is kl-f8-anime2 ?颜色问题:查VAE是否为kl-f8-anime2?
GhostMix V1.2 is an absolutely astonishing model, and I think it is the strongest 2.5D model in Civitai right now. I think a update of the model should improve the model’s compatibility, good image rate and image details given the main structure of 90% generated images doesn’t change. So I use layer combination to combine models layer by layer. And I got this model after 9 different versions of “the final version of GhostMix V1.2”,LOL.This version of GhostMix V1.2 is a balance in terms of compatibility, good image rate and image details, although sometimes using the same Promts of GhostMix V1.1, may comes up a different result.But this doesn’t happen too much.

PS: The first image of GhostMix V1.2 is a nod to Mamoru Oshii’s version of Ghost in Shell in 1995, and my name Ghost_Shell is also a nod to this movie.

中文更新说明
GhostMix V1.2是绝对让你惊艳的模型,也是自己认为现在最强的2.5D模型。我认为模型的更新应该是基于现有的画面整体不大变的前提下,提高模型的成图率,兼容性和画面细节。所以我采用了分层融合,一共做了9个版本的“GhostMix V1.2最终版本”,最终得到了现在这个版本的GhostMix V1.2。这个版本的GhostMix V1.2在兼容性,成图率和画面细节表现比较平衡,虽然有时候会出现同样的Promts,出图改变的情况,但实测不多。
PS:GhostMixV1.2的头图是致敬1995押井守版Ghost in Shell 攻壳机动队的生成的,Ghost in Shell也是作者名字的由来。
2023.3.11 GhostMix-V1.0
Introduction(中文简介在下面)
First of all , I want to thank all the people who use this Checkpoint. And this is my first Checkpoint.All the sample image can be reproduced. This Checkpoint works well on both SFW and NSFW.THE NSFW PART IS VERY GOOD!!!
I uploaded this Checkpoint yesterday and from yesterday to today , I am still trying all the possibility of this Checkpoint. So if you try the model and find some good promts , I hope you can upload it and share with me, it will help me for the next version of GhostMix, Thank you agian!
Recommend Some Promts:
Fractal Art(highly recommend,awsome)
(masterpiece, top quality, best quality, official art, beautiful and aesthetic:1.2), (1girl:1.3), (fractal art:1.3),
Color Art
(flat color:1.3),(colorful:1.3),(masterpiece:1.2), best quality, masterpiece, original, extremely detailed wallpaper, looking at viewer,1girl,solo,floating colorful water
VAE&Textual Inversion:
VAE: kl-f8-anime2 or vae-ft-mse-840000-ema-pruned(anime suggest: kl-f8-anime2)
Textual Inversion: ng_deepnegative_v1_75t, easynegative
About Image Reproduction:
Some user said that they can not reproduce my result.Maybe the setting goes wrong.I just reproduce my cover image. If you want to reproduce my result, Checkpoint Model,Postive Promt,Negative Promt,Textual Inversion,Sampler Steps,Sampler,CFG,Resolution,Seed , ALL the things should be the SAME! Then be careful if you open controlnet or lora ,don't make them influnence your result.
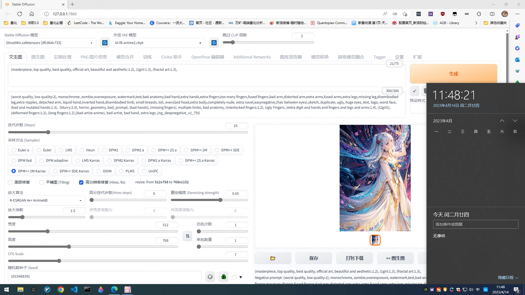
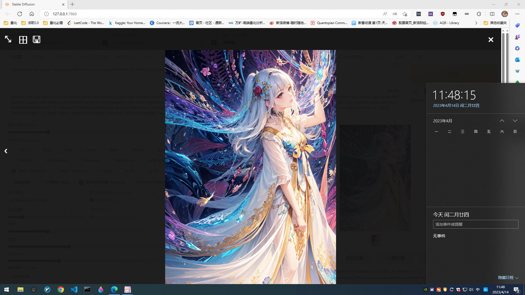
中文简介
首先感谢每一个使用这个Checkpoint的人,这是我融的第一个Checkpoint。所有样图自测都可以复现。SFW和NSFW的图都挺漂亮的,NSFW的图非常棒。这个模型昨天上传到今天,我一直在尝试这个模型的可能性。希望使用这个Checkpoint的朋友们,如果你试了,觉得有不错Promts,欢迎上传图分享,让我也了解一下这个Checkpoint的可能性,也可以帮助我调下一个版本GhostMix,再次感谢。
推荐Promts:
分型艺术(超级推荐,必出好图)
(masterpiece, top quality, best quality, official art, beautiful and aesthetic:1.2), (1girl:1.3), (fractal art:1.3),
色彩艺术
(flat color:1.3),(colorful:1.3),(masterpiece:1.2), best quality, masterpiece, original, extremely detailed wallpaper, looking at viewer,1girl,solo,floating colorful water
VAE&Textual Inversion:
VAE:kl-f8-anime2或者vae-ft-mse-840000-ema-pruned(动画风建议kl-f8-anime2)
Textual Inversion:ng_deepnegative_v1_75t,easynegative
关于图片复现:
有同学好像没法复现我的图,可能是设置有点问题,刚刚我才把头图给复现了。注意几个点:Checkpoint 模型,正向Promt,反向Promt,Textual Inversion,迭代步数,迭代方法,CFG,分辨率,随机种子都必须一模一样!然后复现的话,要把controlnet和lora关掉,怕影响复现。