WrenchMix
файл на civitaiстраница на civitaiThis is a merge of my 3 favorite models/mixes:
MothMix
Pastel-Mix [Stylized Anime Model]
This merge started as a curious question with other people at civitai discord, "What will happen if i 50/50 merge Rev Animated with Mothmix?" The results were great. So I tried merging Pastel-mix in it too to give that pastely effect but keeping the properties of previous merge. And this is the result. I hope it didn't caught my bad hands curse.
NOTE: This mix is based on my personal tastes.
Recommended config
Sampler: DPM++ 2M Karras
Sampling Steps: 25-40
Upscaler: 4x-UltraSharp
CFG Scale: 5-10 (what I usually use with any model)
Denoising strength: 0.2-0.7
Clip Skip: 2
Vae: None(if you want washed style), Blessed-fix
Enable Quantization in K samplers
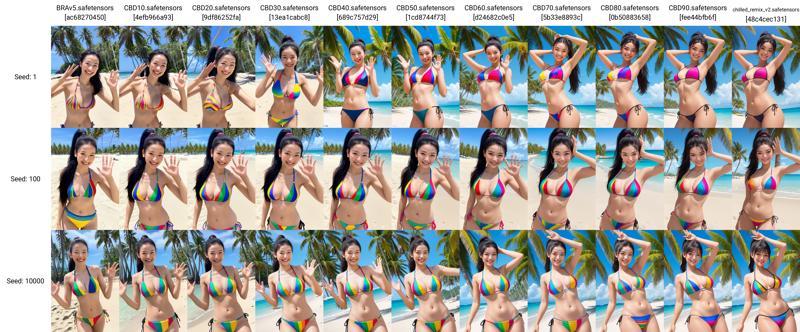
The images are not cherry picked, these are simple hires fix 2x upscaled images that are generated while reviewing few chan LoRA that we people at civitai discord server been working on. Although some seeds were repeated with updated prompts to get details like hands, extra limbs correct.
Credits
Author of Rev Animated: s6yx
Author of Pastel-Mix [Stylized Anime Model]: andite
Author of MothMix: bombasticmori
Do check their content and support them for their amazing work.
Recipe
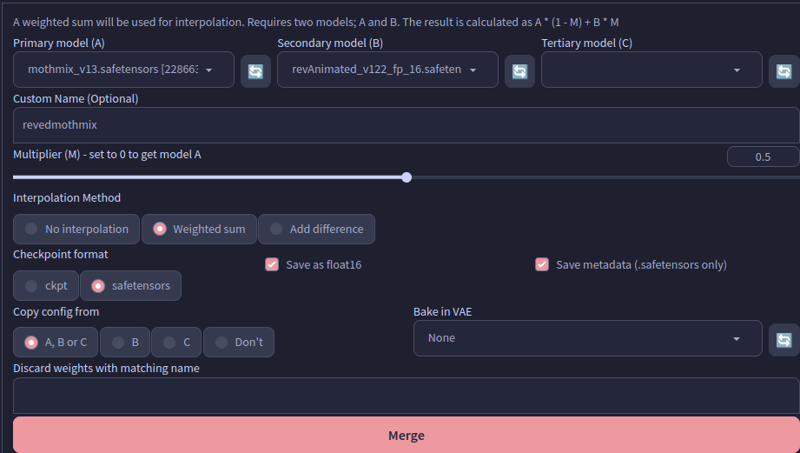
As a software dev, I don't like to make simple things complex. So here are the exact screenshots of the merge window.
NOTE: ReV Animated was first pruned to fp16 since I like to keep them as small as possible.
Step 1:
Step 2:
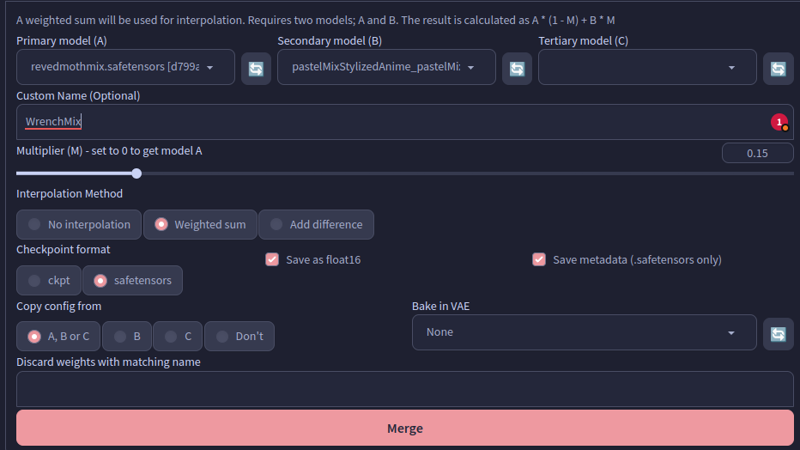
Easy as that.
License
This model is open access and available to all, with a CreativeML OpenRAIL-M license further specifying rights and usage. The CreativeML OpenRAIL License specifies:
1. You can't use the model to deliberately produce nor share illegal or harmful outputs or content
2. The authors claims no rights on the outputs you generate, you are free to use them and are accountable for their use which must not go against the provisions set in the license
3. You may re-distribute the weights and use the model commercially and/or as a service. If you do, please be aware you have to include the same use restrictions as the ones in the license and share a copy of the CreativeML OpenRAIL-M to all your users (please read the license entirely and carefully)Please read the full license here
Disclaimer
The use of this learning model is entirely at the discretion of the user, and they have the freedom to choose whether or not to create NSFW content.
This is important to note that the model itself does not contain any explicit or inappropriate imagery that can be easily accessed with a single click.
The purpose of sharing this model is not to showcase obscene material in a public forum, but rather to provide a tool for users to utilize as they see fit.
The decision of whether to engage with SFW or NSFW content lies with the user and their own personal preferences.