Loraを使い、作り、投稿の作業フロー 2023/04/13 16:40 更新
AI素人です
知識はそんなに深くないので難しい事はあまり書かないです
ダウンロード数が増えるとたぬきが喜びます ハートが増えるとたぬきのHPが回復します
そもそもLoRAって何?の説明
ざっくりとした説明
stablediffuisonというソフトで使われている学習済モデル(pretraind model 5GBくらい)そのままでは新しい絵が出せないので追加で学習させたい。
でもデータ全体が変更される学習方法だとすごく大変なのでLoRAっていう限定的な学習方法で現実的なコスト(データ量・計算時間)で出来るようになったよ!
新しい絵を学習させて、それが使えるようになるという理解。
https://qiita.com/ps010/items/ea4e8ddeff4de62d1ab1
Stable Diffusionの特徴は、次の3つです。
Stable Diffusionは、最近流行の Diffusion Model(拡散モデル)をベースとしたtext-to-imageの画像生成モデルです
VAEでピクセル画像を潜在表現に変換することで、モデルの軽量化に成功しました
U-Netを用いた画像生成の条件づけにText EncoderのCLIPを使用します
https://dosuex.com/entry/2023/03/30/115101
LLMの課題
近年、LLM(大規模言語モデル)が多くの自然言語処理タスクで顕著な成果を上げています。一般的に、これらのモデルは非常に多くのパラメータを持っており、特定のドメインやタスクへの適応を行う際には、大量のデータと計算リソースが必要となることが課題となっています。また、モデルのサイズが大きくなることで、デバイスのメモリや計算能力が制約される環境での使用が困難になる場合もあります。
LoRAの目的
LoRA(Low-Rank Adaptation)は、この課題に取り組むためにMicrosoftによって開発されました。LoRAの目標は、LLMのパラメータを低ランク行列で近似することにより、適応の際に必要な計算量とメモリ使用量を大幅に削減し、タスクやドメイン固有のデータで迅速かつ効率的にモデルを微調整することができるようにすることです。これにより、LLMをより実用的で効果的なツールに進化させることが期待されています。
元々LLMの学習コストを下げる為に考えられた方法をstablediffusionに応用したという感じ?
------------------------------------------------------------------------------------------------------
閑話休題
学習する為のPCの推奨
OS Win11
CPU 最近のならなんでもよい
RAM 32GBくらいあれば動くはず
SSD 読み書きが早くなります
GPU GeforceRTX VRAM8GBが最低ライン、6GBは設定を突き詰めれば?、12GB以上あると安心?
Webブラウザ firefoxとchromeとEdgeの最新バージョン
前提となる環境/ソフトウェアの導入 Win11/Geforce
Geforce Experience導入(共通)
https://www.nvidia.com/ja-jp/geforce/geforce-experience/

webui automatic1111導入(windowsローカル編)
git
https://gitforwindows.org/

ダウンロードして実行してインストール
設定は弄らずにそのままでいけた筈
インストール後
パワーシェルで

git

インストールされているのを確認
python
https://www.python.org/
python3.10.6をインストール
https://www.python.org/downloads/windows/

最近のWin11機であれば64bitだと思います。32bitで動かしているのは知らないです。
anaconda3やminicondaはインストールしない想定で書いています。
Windowsストアからもアプリ版のpythonが入れられるようですが確認していません。
解説サイトでも扱いが無いのであまりおすすめ出来ないです。
インストール後、Windowsの検索からpowershellを検索し実行

パワーシェルで
python -V
を実行、バージョンが表示されていればインストールされています。
インストールしてもpythonが見つからない場合はパスの設定がおかしいです。

この場合はPython 3.10.10が入っていますが特に問題無く動いています。

バージョンがだいたいあっていればだいたい動くし動かない事もある
webuiでもsd-scriptでも3.10.6バージョンが安定しているようです。
PyTorch のインストール(Windows 上)※1引用
コマンドプロンプトとパワーシェルは別環境なので、パワーシェルに読み替えて下さい。
Windows で,コマンドプロンプトを管理者として実行
コマンドプロンプトを管理者として実行:
PyTorch のページを確認
PyTorch のページ: https://pytorch.org/index.html
次のようなコマンドを実行(実行するコマンドは,PyTorch のページの表示されるコマンドを使う).
次のコマンドは, PyTorch 2.0 (NVIDIA CUDA 11.8 用) をインストールする.
事前に NVIDIA CUDA のバージョンを確認しておくこと(ここでは,NVIDIA CUDA ツールキット 11.8 が前もってインストール済みであるとする).
https://developer.nvidia.com/cuda-11-8-0-download-archive

Windows x86_64 11 exe(local)を選択、赤矢印にダウンロードリンクが出るので落とす
そして実行する

一行ずつ実行していってね!
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118
python -c "import torch; print(torch.__version__, torch.cuda.is_available())"
pip installするとだーっと進捗が表示されて終わったらpython -cでtorchがインストールされているのか確認します
torchのバージョン1.13とか1.12とか2.0が表示されたら入っていると思います
Automatic Installation on Windows
エクスプローラーで導入したい場所のフォルダを右クリックして
ターミナルで開く を実行

git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui.git
webui-user.bat をエクスプローラーから実行
1.をパワーシェルにコピペして実行
処理が終わるとフォルダにwebui-user.batが作られているので実行する
webブラウザから http://127.0.0.1:7860 を開く(http://localhost:7860 でもokな筈)
(設定で自動でブラウザで開くようにも出来ます。)
導入以降はwebui-user.batを実行するようになります。
web-user.batの中身
@echo off
set PYTHON=
set GIT=
set VENV_DIR=
set COMMANDLINE_ARGS=
call webui.bat
VRAM4GB以下向けオプション
VRAM消費量を低減する代わりに速度が犠牲になるとのこと。
set COMMANDLINE_ARGS=--medvram
↑で out of memory が出た場合
set COMMANDLINE_ARGS=--medvram --opt-split-attention
↑でもまだ out of memory が出た場合
set COMMANDLINE_ARGS=--lowvram --always-batch-cond-uncond --opt-split-attention
その他のオプション
--xformers (高速化/VRAM消費減)
torch2.0なら無くても良い 環境による
--opt-channelslast (高速化)
1111のWikiのよると、Tensor Coreを搭載したNVIDIA製GPU(GTX16以上)で高速化が期待できるとのこと。
--no-half-vae (画像真っ黒対策)
真っ黒になった時に
--ckpt-dir(モデルの保存先を指定する。)
保存先を変えたい時に
--autolaunch (自動的にブラウザを立ち上げる)
いちいちWebブラウザにアドレスを入れるのが面倒な時に
--opt-sdp-no-mem-attention または --opt-sdp-attention
(Torch2限定
xformersと同じく20%前後高速化し、出力にわずかな揺らぎが生じる。VRAM消費が多くなる可能性がある。
AMD Radeon,Intel Arcでも使える。)
--device-id 0 (複数枚GPUが刺さっている場合に指定する、0から始まる。デフォルトでは0を使う。)
set PYTORCH_CUDA_ALLOC_CONF=garbage_collection_threshold:0.6,max_split_size_mb:24
PytorchでCUDAがメモリを使う時の設定
閾値6割メモリが使われたら 24MB単位でGarbageCollectionするよ(メモリ上の使われていないデータを掃除、消費メモリが減る。のでCUDAがOutOfMemoryを表示して落ちなくなる・・・という願い。)
拡張機能によっては相性が悪かったりするのでreadmeをよく読んで使って下さい!
初期設定で起動すると自動でckptをダウンロードするのでしばらく時間が掛かります
sd-script導入
パワーシェルでコマンドが実行出来るように権限を設定

powershellをスタートメニューから検索して右クリックして管理者として実行をクリックしてください
パワーシェルを開いて以下を一行ずつ実行
git clone https://github.com/kohya-ss/sd-scripts.git
cd sd-scripts
python -m venv venv
.\venv\Scripts\activate
pip install torch==1.12.1+cu116 torchvision==0.13.1+cu116 --extra-index-url https://download.pytorch.org/whl/cu116
pip install --upgrade -r requirements.txt
pip install -U -I --no-deps https://github.com/C43H66N12O12S2/stable-diffusion-webui/releases/download/f/xformers-0.0.14.dev0-cp310-cp310-win_amd64.whl
cp .\bitsandbytes_windows\*.dll .\venv\Lib\site-packages\bitsandbytes\
cp .\bitsandbytes_windows\cextension.py .\venv\Lib\site-packages\bitsandbytes\cextension.py
cp .\bitsandbytes_windows\main.py .\venv\Lib\site-packages\bitsandbytes\cuda_setup\main.py
accelerate config
LoRA_Easy_Training_Scripts 導入
v5以前の場合
https://github.com/derrian-distro/LoRA_Easy_Training_Scripts/releases
.batをダウンロードして配置したいフォルダで実行する
v6の場合
Release installers v6 · derrian-distro/LoRA_Easy_Training_Scripts (github.com)
installer.pyを導入したいフォルダに配置して

ターミナルを開いてパワーシェルで
python installer.py を打ち込み実行
途中色々ダウンロードされるので待ちます
Do you want to install the optional cudnn1.8 for faster training on high end 30X0 and 40X0 cards? [Y,N]?
と聞かれるので30x0/40x0シリーズのグラボを使っている場合はYを入力、それ以外のグラボはNを入力してください
sd-scriptが入りますが設定が終わっていないので
パワーシェルで一行ずつ実行してください
cd sd-scripts
venv\Scripts\activate
accelerate config
共通
accelerate configで次のように答えて下さい
- This machine
- No distributed training
- NO
- NO
- NO
- all
- fp16 (数字キーの1を押してリターンで選びます、矢印キーで操作しようとするとエラーで落ちます)
webui簡単インストーラー版
https://github.com/AUTOMATIC1111/stable-diffusion-webui/releases/tag/v1.0.0-pre
The webui.zip is a binary distribution for people who can't install python and git.
Everything is included - just double click run.bat to launch.
No requirements apart from Windows 10. NVIDIA only.
After running once, should be possible to copy the installation to another computer and launch there offline.
webui.zip は、python と git をインストールできない人向けの環境です。
すべてが含まれています - run.bat をダブルクリックして起動するだけです。
Windows 10 以外の要件はありません。
NVIDIA のみ。
一度実行した後、インストールを別のコンピューターにコピーして、オフラインで起動できるはずです。
使っていないので解説出来ませんが、お手軽そうですね。
Win10の環境が無いので検証できませんので他の方の記事を参考にして下さい。
LoRA ファイルについて
階層見本
stable-diffusion-webui
┗models
┗lora この中に使用したい学習データを保管します。
LoRAで使用可能なデータは「.safetensors」「.ckpt」の拡張子です。
識別子を使用する場合、プロンプトに識別子を記述することを忘れないようにしましょう。
CIVITAIではpnginfoのLoRAファイル名とダウンロードされるLoRAファイル名が異なるので
自分で書き換える作業が必要になるかと思います。
ファイル名書き換えるか、プロンプトの方を書き換えるかです。
学習用データセットの準備
画像を用意する
(画像が少なければ反転・切り取りなどを駆使)極論すれば一枚あればどうにか出来るらしい?
ファイルをフォルダに配置する。(正則化画像は説明がめんどくさいのでいつか書く)
targetが学習させたいものの名称だと思って下さいね
ファインチューン向けメタデータの作成方法
(jsonファイルを読み込んで学習させる場合)
kyousi(フォルダ)
target(フォルダ)
target000.jpg(画像ファイル)
target001.jpg(画像ファイル)
webui automatic1111の拡張機能のwd1.4taggerでタグ付けバッチ処理をする
(他の使った事無いのでベストかどうかは分からない)
バッチ処理の入力フォルダの画像を読み込んで、出力フォルダに画像枚数だけ.txtファイルを書きだす。
ディレクトリ一括処理 タブを選んで
入力ディレクトリにtargetを指定
出力ディレクトリにtargetを指定
重複するタグを削除(としあき製のタグクリーナーを使う場合は✅要らない)
JSONで保存(としあき製のタグクリーナーを使う場合は✅要らない)
インタロゲーターを指定できますがデフォルトのを使用しているので違いは良く分かりません

インタロゲートのボタンを押すとバッチ処理が始まり、CMD窓(webui-user.batを実行すると開く窓)に進捗が表示され全て終了すると all done :) が表示されます。


Dataset Tag Editorでは
Wd1.4 taggerで作った.txtファイルや.jsonファイルを指定してタグを編集出来るようです。
ファインチューン用jsonファイル作成バッチ
wikiで書かれている作成バッチのテキストをnotepadにコピペしてmake_json.batとか適当に名前を付けて保存
taggerで作られた.txtファイルを.jsonファイルにする。
rem ----ここから自分の環境に合わせて書き換える----------------------------------
rem sd-scriptsの場所
set sd_path="C:\LoRA_Easy_Training_Scripts\sd_scripts"
rem 学習画像フォルダ
set image_path="C:\train\kyousi\"
rem ----書き換えここまで--------------------------------------------------------
.batをnotepadで開いてフォルダの場所だけ書き換えます。
そして.batを実行

メタデータにキャプションがありませんと表示されますが気にしません(メタデータとかキャプションについてはよくわかりません)

merge_clearn.jsonの内容を編集します
.jsonファイルの内容を見てトリガーワード(にしたいタグ)があったらそのまま、無ければ一番最初の位置に追加する(--keep_tokens=1と--shuffle_captionを指定する為)。
"C:\\Users\\watah\\Downloads\\kyousi_78\\siranami ramune\\100741149_p0.jpg": {
"tags": "siranami ramune,1girl, virtual youtuber, solo, v, fang, multicolored hair, blue jacket, blue hair, choker, hair behind ear, smile, crop top, bangs, streaked hair, hair ornament, jewelry, looking at viewer, earrings"
},
サンプルです。
.jsonファイルは上のような3行1セットな書き方をされています。画像ファイルの数だけセットがあると思って下さい。
”画像ファイルのパス”:{
”tags”:”token1,token2,,,,,,(略)”
},
token1でトリガーワードにしたいタグ(ややこしいですね)を入れます。
私はテキストエディアの置換で全部書き換えています。
置換元 -> 置換先
"tags": " -> "tags": "トリガーワード,
--shuffle_caption
これは各タグをシャッフルしてタグの重みを分散させる効果があるのだとか。
--keep_tokens=1
1番目のタグまでを保持(この場合は1番目にあるtoken1)にします。
トリガーワードを1つで強く効かせたいのでこのような設定をしています。
理論的な解説は他の方におまかせします。
sd-scriptで学習を実行。

venvの仮想環境に入ってコマンド直打ち、もしくはtoml設定ファイルを使用する。
sd-scriptのフォルダを右クリックしてターミナルを開く
venv/Scripts/activateと入力してvenv(仮想環境)に入る

コマンドをコピペして実行
(改行を入れない、使いまわししてる設定は見やすくするために改行を入れています。また設定値は適宜変更して下さい。)

コピペして実行すると流れてくるのはこんな感じ



画像枚数 x 繰り返し回数 x 総epoch / バッチサイズ = 総ステップ数
経過時間 残り時間 処理速度 it/s loss
lossはよくわかりません監視しても意味が無いというのを見かけましたが諸説あると思います。

(LoRAの場合)ステップ数6000くらいになるようにepochとrepeatを適当に弄る。
特に根拠はありません。最適な数値は自分で模索しましょう。
私の環境では所要時間一時間弱。だいたい 1.80it/sくらいの速度。
出来上がったLoRAをwebuiのLoRAフォルダに入れてwebuiを立ち上げる。
lokrは4000ステップくらいで回してますけどベストかどうかはよくわからないです・・・・誰か教えて


インストール先で変わってくると思いますが多分ここら辺
F:\stable-diffusion-webui\models\Lora
にLoRA(拡張子.safetensorファイル)を設置してください
webuiの使い方

webui-user.batを選んでダブルクリック

何事も無ければRunnning on local URL: http://127.0.0.1:7860 と最後に表示されます
webuiは拡張機能により日本語化されています
設定値をマニュアルで弄る方法もあります
☠加筆修正中☠
日本語化拡張適用済

・サンプリング方法
サンプリングアルゴリズム
個人的にはDPM++ 2Mが早くて良い感じに描いてくれる気がする、諸説ある。
・サンプリングステップ数
20-50の間くらいで、大きい数字入れてもクオリティが比例して上がるわけではないし時間が掛かる。諸説ある。
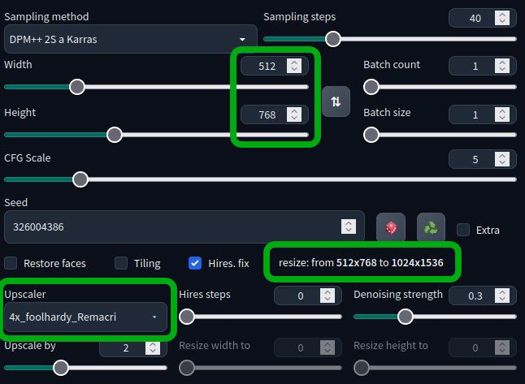
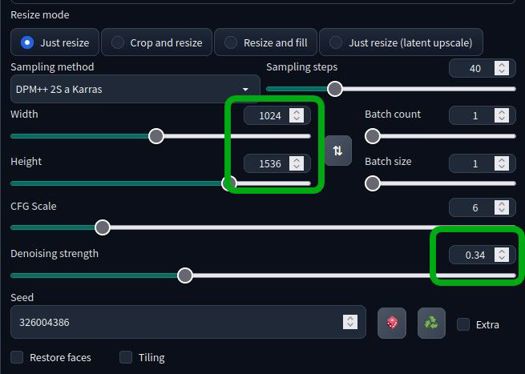
・高解像度補助(hires.fix)
高解像度にする時に画像が崩れるのを防ぐ
・アップスケーラー
拡大するアルゴリズム
アニメ系はR-ESRGAN 4x+ Anime6Bがいいらしい。諸説ある。
・アップスケール比率
拡大倍率
・高解像度でのステップ数
高解像度でどのくらいステップ数を使って再描画するか
迷ったらサンプリングステップ数と同じにしたらどうかな
・ノイズ除去強度
・バッチ回数
合計何枚の絵を一度に作るのか
・バッチサイズ
一度に作る画像の数 VRAM少ないなら1でいい、多いなら4とか?
・幅
作りたい画像の横のサイズ
・高さ
作りたい画像の縦のサイズ
・CFGスケール
高いほどpromptの内容に忠実に従うような動きをする
・シード
同じseed値を使うと同じ画像が作成される
気が付かずに何枚も似たような絵が出てきてようやく気が付く
-1でランダム
png内部の情報をsend2でtxt2imgで開いた時は固定値になるので気を付けようね!(絵を再現する為)

・ポジティブプロンプト
こうやって欲しいという指示を,で区切って指定する
・ネガティブプロンプト
こういうのは嫌という指示を,で区切って指定する
・生成
絵を生成するよ
プロンプトを調整する。
この辺りはCIVITAIで投稿されている画像から知恵を拝借するといいかも
複数枚絵を生成して出来栄えが良い物を選別する。
バッチ数を8枚くらいにしてしばし待つ
どうしても結果が芳しくない場合はLoRAのepochの小さいものを使うか、
さらにLoRAに学習を続ける。
sd-scriptで学習する時に --save_every_n_epochs=1 とすると1epochごとにセーブされるます
通常last.safetensorから試しますが過学習かな?となった時に小さい数値のepochで試していくというやり方をしています

コピペ直打ちする時に--network_weights="hogehoge.safetensor"で指定するとLoRAファイルにさらに学習させられます。
学習が足りないかな?というときに
waifu diffusion1.5beta2-aesthetic導入メモ
https://huggingface.co/waifu-diffusion/wd-1-5-beta/blob/main/checkpoints/wd15-beta1-fp16.safetensors
https://huggingface.co/waifu-diffusion/wd-1-5-beta/blob/main/checkpoints/wd15-beta1-fp16.yaml
https://huggingface.co/waifu-diffusion/wd-1-5-beta/blob/main/checkpoints/wd15-beta1-fp32.safetensors
https://huggingface.co/waifu-diffusion/wd-1-5-beta/blob/main/checkpoints/wd15-beta1-fp32.yaml
https://huggingface.co/waifu-diffusion/wd-1-5-beta/blob/main/embeddings/wdbadprompt.pt
https://huggingface.co/waifu-diffusion/wd-1-5-beta/blob/main/embeddings/wdgoodprompt.bin
stable-diffusion-webui
|-- embeddings
| |-- wdbadprompt.pt
| `-- wdgoodprompt.bin
|-- models
| `-- Stable-diffusion
| |-- wd-1-5-beta2-aesthetic-fp16.safetensors
| `-- wd-1-5-beta2-aesthetic-fp16.yaml
`-- 〜省略〜
ファイルの設置はこれで良い筈
そして満足いく結果が得られたらいよいよCIVITAIに投稿です!
CIVITAIに投稿する
たしか登録しないと投稿出来なかった筈
discoad
reddit
google
github
アカウント連携で登録できたと思います
四つの内どれかのアカウントあればそのアカウントで認証出来ます
無くても新規登録は出来た筈
登録終わってloginしていると想定して話を進めます

さっそくモデルを投稿していきたいと思います(80回目)

なまえ
公開する時に表示されるなまえ
ファイルタイプ
LoRAとかLyCORIS(Locon/LoHA)とか選べます
付与するタグ
+を押して付けたい単語を入力します
無ければ新規に作って登録します
モデル説明
モデルがどういうものかを説明すればいいと思います
商業利用
下の方に説明があります スクロールして読んでください
現実に実在する人物か?
実在する人物は肖像権の関係があります
Is intended to produce mature themes only
多分だけど成人した人物のみを扱いますとかそんな感じだと思う。
FBIに通報されるようなデータを作らないでね
CIVITAIでの投稿時に注意すべき個人的ポイント

左のを意訳
このモデルを使う時にユーザー許可する内容
私の名前(この場合watahanを)を表記しなくていいです
このモデルのマージを共有してください
マージには異なる許可を使用する
右のを意訳
商業利用
全部禁止
生成した絵を販売する
AI絵生成サービスで使用する
このモデルまたはマージしたものを販売する
二次創作は二次創作ガイドラインがある場合、規約に従ってください。
モデルのタイトルにUnOfficialと必ず入れているのは公式だと誤認させない為です。

バージョン
好きなように付けて下さい
アーリーアクセス
早期アクセスよくわからないけど公開するまでの日数が設定出来るぽい
ベースモデル
SDのどのバージョン系列かを選ぶ
分からない場合はotherにする
トリガーワード
LoRAを使う時に使うトリガーワードを書いてください
無いとDLした人が使う時に困ります
学習時のepoch
学習させたときのepoch数を入力
学習時の総ステップ数
学習させたときの総ステップ数を入力

ckpt pt safetensor bin zipなどの拡張子のファイルがアップロードできます
クリックして開くかドロップする

アップロードするファイル名
ローカルのファイル名が表示されます 違うファイルを選んだときはゴミ箱アイコンで削除出来ます
ファイルタイプ
選んでください
アップロードを始める
実際にファイルをアップロードします

投稿する画像ファイルをここから開くかドロップしてね
投稿するタグは必ず一つは設定しないと公開できないので+Tagで追加してください
既存に無ければ新規にタグを作ります
最後にpublish押して公開されます
これでCIVITAIのみんなにあなたの作ったLoRAファイルが公開されましたね
pnginfoは編集しないでそのまま載せてるのでLoRAファイル名を弄るだけで再現出来る筈(CIVITAIがファイル名を変更している為)。
ToME入れてるので背景のディテールが違う?xformersとかでも微妙に違って来るらしいがよくわかりません
VAEファイルを入れるとまた変わってくると思います よく使われるのにEasyNegativeとかあります
https://github.com/kohya-ss/sd-scripts/blob/main/train_README-ja.md
LoRA以外にも追加学習について書かれています。一読しましょう。
LoRAとかの拡張とかのメモ
https://scrapbox.io/work4ai/LoCon

LoRAは緑の部分しか学習していないが、LoConは黄色の部分を学習できるので、合わせてほぼすべてのレイヤーをカバーできる
上の図はConv2d-3x3拡張とはまた別なのだろうか?
https://scrapbox.io/work4ai/LyCORIS

左の図が2R個のランク1行列(縦ベクトルと横ベクトルの積)の総和になるのに対し、右の図はRの2乗個のランク1行列の総和になるので同じパラメータ数でランクを大きくできるらしい。
[(IA)^3]
This algo produce very tiny file(about 200~300KB)
実装 : [. https://github.com/tripplyons/sd-ia3]
>[LoRA]との大きな違いは、(IA)^3はパラメータの使用量がかなり少ないことです。一般的には、高速化・小型化される可能性が高いが、表現力は劣る。
lokr
LyCORIS/Kronecker.md at b0d125cf573c99908c32c71a262ea8711f95b7f1 · KohakuBlueleaf/LyCORIS (github.com)
行列をなんやかやするらしいが解説出来ないです
Dylora
出たばかりなのでよくわかりません
LoCon拡張とLyCORIS拡張 メモ
a1111-sd-webui-locon:[lora]フォルダにある Lycoris (Locon)ファイルを判別、処理する。
<lora:MODEL:WEIGHT>
a1111-sd-webui-lycoris:[Lycoris]フォルダにある Lycoris (Locon)ファイルを処理する。プロンプトから重みづけ指定が可能。
<lyco:MODEL:TE_WEIGHT:UNET_WEIGHT>
Model名とTextEncoderのweightとu-netのweightを設定してやらないといけないのですね
予定
LoRAのリサイズ、階層別マージも時間があればやりたい。
メモ 使いまわし設定の一部を変更してLyCORISを使う
LoCon使う時
--network_module lycoris.kohya
--network_dim=16
--network_alpha=8
--network_args "conv_dim=8" "conv_alpha=1" "dropout=0.05" "algo=lora"
LoHA使う時
--network_module lycoris.kohya
--network_dim=8
--network_alpha=4
--network_args "conv_dim=4" "conv_alpha=1" "dropout=0.05" "algo=loha"
ia3使う時(検証してない)
--network_module = lycoris.kohya
--network_dim = 32
--network_alpha=16
--network_args = "conv_rank=32", "conv_alpha=4", "algo=ia3"
--learning_rate = 1e-3
lokr使う時
--network_module lycoris.kohya
--network_dim=8
--network_alpha=4
--network_args = "conv_rank=4", "conv_alpha=1", "algo=lokr",”decompose_both=True”,”factor=-1”
--unet_lr=3.0e-4
--text_encoder_lr=1.5e-4
消費メモリの削減
--gradient_checkpointingオプションを付けると学習速度が遅くなる代わりに消費メモリが減る。
消費メモリが減った分バッチサイズを増やせば全体の学習時間は速くなる。
公式のドキュメントにはオンオフは学習の精度には影響しないとあるため、
VRAMが少ない環境では学習速度の改善には--gradient_checkpointingオプションを追加してバッチサイズを増やすのが有効。
参考
VRAM8G、LoHa、512 x 512の場合、バッチサイズ15まで動作できることを確認。
VRAM8G、LoHa、768 x 768の場合、バッチサイズ5まで動作できることを確認。
SD2.0以降を学習時のベースモデルに使う場合
--v2
--v_parameterization
--resolution=768,768
768サイズで学習させているベースモデルなので
追加学習時に解像度を768設定してみます
新しい投稿からlokrに切り替えてみました。
1.13it/s --optimizer_type lion
1.33it/s --use_8bit_adamW
どうも学習が上手く行かないのでLoRAに戻してみます、lokrはちょっとピーキーな感じがする・・・。
optimizerにlion使うには
sd-scriptフォルダを右クリックでターミナルで開くを選び
venv/Scripts/activate
pip install lion-pytorch
で導入しておきます
https://github.com/lucidrains/lion-pytorch
--optimizer_type lion
tomlファイル使うと楽になるらしいです
--config_file で .toml ファイルを指定してください。ファイルは key=value 形式の行で指定し、key はコマンドラインオプションと同じです。詳細は #241 をご覧ください。
ファイル内のサブセクションはすべて無視されます。
省略した引数はコマンドライン引数のデフォルト値になります。
コマンドライン引数で .toml の設定を上書きできます。
--output_config オプションを指定すると、現在のコマンドライン引数を--config_file オプションで指定した .toml ファイルに出力します。ひな形としてご利用ください。
参考にした情報
ふたば may AIに絵を描いてもらって適当に貼って適当に雑談するスレ 不定期
としあきwiki 上のスレのまとめ
なんJ なんか便利なAI部 5ch
/vtai/ - VTuber AI-generated Art 4ch
くろくまそふと
経済的生活日誌
Gigazine
原神LoRA作成メモ・検証
AIものづくり研究会@ディスコード
[Guide] Make your own Loras, easy and free@CIVITAI
githubのreadme sd-scriptとLyCorisとautomatic1111辺り 細かい設定や変更点・バグなどがあるので検索だけでは分からない事があります
使いまわししてる設定
--max_train_epochs --dataset_repeats --train_data_dirだけ変えています。
accelerate launch --num_cpu_threads_per_process 16 train_network.py
--pretrained_model_name_or_path=C:\stable-diffusion-webui\models\Stable-diffusion\hogehoge.safetensors
--train_data_dir=C:\Users\hogehoge\Downloads\kyousi\
--output_dir=C:\train\outputs
--reg_data_dir=C:\train\seisoku
--resolution=512,512
--save_every_n_epochs=1
--save_model_as=safetensors
--clip_skip=2
--seed=42
--network_module=networks.lora
--caption_extension=.txt
--mixed_precision=fp16
--xformers
--color_aug
--min_bucket_reso=320
--max_bucket_reso=512
--train_batch_size=1
--max_train_epochs=15
--network_dim=32
--network_alpha=16
--learning_rate=1e-4
--use_8bit_adam
--lr_scheduler=cosine_with_restarts
--lr_scheduler_num_cycles=4
--shuffle_caption
--keep_tokens=1
--caption_dropout_rate=0.05
--lr_warmup_steps=1000
--enable_bucket
--bucket_no_upscale
--in_json="C:\train\marge_clean.json"
--dataset_repeats=5
--min_snr_gamma=5
学習時のベースモデルはAOM2を使っています
いわゆる1.4系?ですけど使用モデルをotherにしています
絵を生成する時はAOM2・AOM3・Counterfeit-V2.5・Defmix-v2.0辺りの相性は良さそうです
個人の好みの話になってくると思いますので好きなモデルでお試しください
XYZ plotでモデルを一通り試すといいかもしれません
※1引用元
https://www.kkaneko.jp/ai/win/stablediffusion.html より引用致しました
使用マシン
OS Win11
RAM DDR4 128GB
GPU 3060 VRAM 12GB
ストレージ HDD何台かとNVMeを二台
Colabでの学習(調べ終わってないのでその内ちゃんと書きます)
webui automatic1111の日本語化拡張レポジトリの方が書いた大変分かり易いcolabの解説記事があったので
紹介します。
Linaqruf/kohya-trainer | GenerativeAI Wiki (katsuyuki-karasawa.github.io)
----------------------------------------
本文終わり
そして
「オレはようやくのぼりはじめたばかりだからな、このはてしなく遠いAI絵坂をよ…」

独り言
プロンプトエンジニアリングとかよくわからない 雰囲気だけでLoRAを作ってるもんで