metadata-marker
файл на civitaiстраница на civitaiI will explain in English and Japanese(日本語).
Please click here for emergencies.
https://twitter.com/hypersankaku2
URL for extension's git repository
https://github.com/new-sankaku/stable-diffusion-webui-metadata-marker.git
--
Installation
On your Stable Diffusion WebUI, click the Extensions tab, then the Install from URL internal tab in that section. Paste the URL for this repo and click Install.
If downloading directly:
Unzip the downloaded Zip file in the "extensions" folder in WebUI.
If installing from within the WebUI:
Click the "install from url" button in the "extensions" tab.
Enter https://github.com/new-sankaku/stable-diffusion-webui-metadata-marker.git
Click the "install" button.
Version1.0
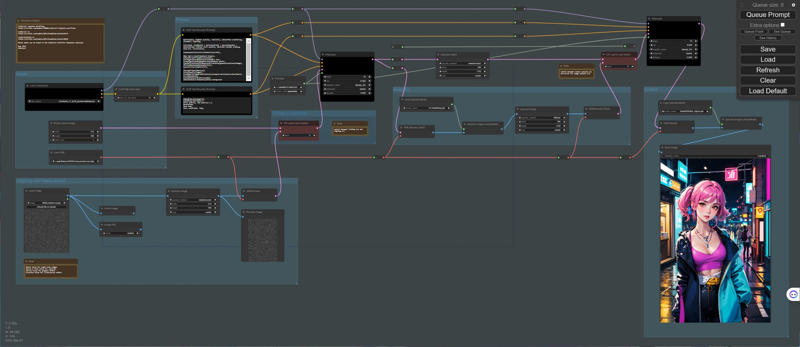
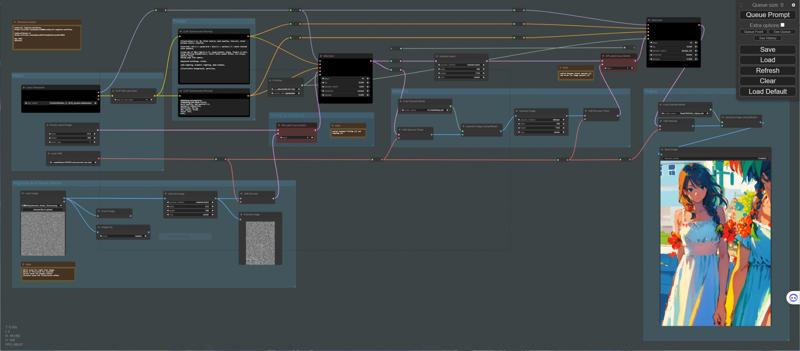
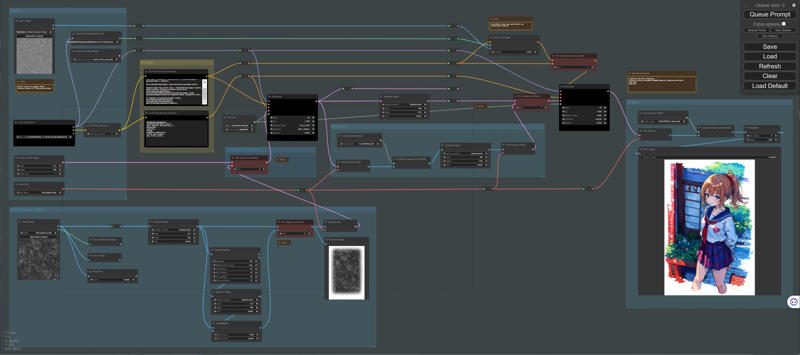
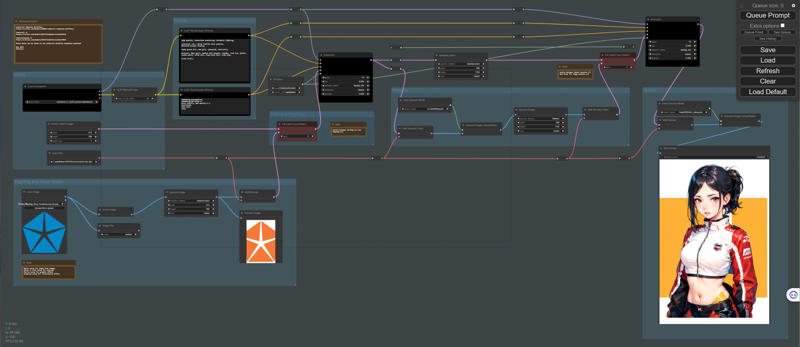
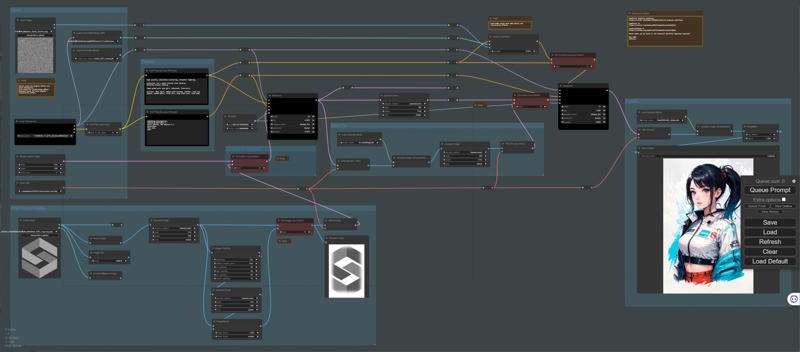
It is an extension of tex2img.
The output image will have generation information rendered on it.
It is designed mainly for verification purposes.
For example, you can verify differences that arise from various prompts.
Additionally, it can be useful when you want to share generated information on Twitter.
This extension has the following features:
You can switch the output image settings.
You can set the information to be rendered on each item.
The font size automatically adjusts based on the image size.
If there is a feature you would like to add, please let us know.
I will accommodate your request if possible.
Version1.1
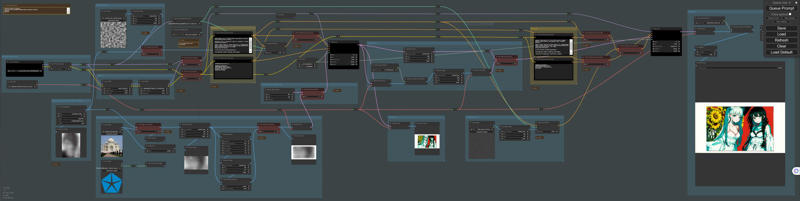
We've added a new feature. This allows us to create a margin around the image and write text in that space. Now, you can add text to your image without covering any important parts of it.
Version1.2
Specify Font Size: Allows users to set a custom font size for the text. Added clear line breaks: Implements line breaks for better readability of the text.
---
急用の際はこちらにどうぞ。
https://twitter.com/hypersankaku2
インストール
Stable Diffusion WebUI で、[拡張機能] タブをクリックし、そのセクションの [URL からインストール] 内部タブをクリックします。 このリポジトリの URL を貼り付け、「インストール」をクリックします。
直接ダウンロードする場合:
ダウンロードしたZipファイルをWebUIの「extensions」フォルダに解凍します。
WebUI 内からインストールする場合:
「拡張機能」タブの「URLからインストール」ボタンをクリックします。
https://github.com/new-sankaku/stable-diffusion-webui-metadata-marker.git と入力します。
「インストール」ボタンをクリックします。
Version1.0
tex2imgのExtensionです。
出力する画像に生成時の情報を描画します。
主に検証用途で使われることを想定しています。
例えば、Promptの違いによる差を確認することができます。
あるいは、生成情報をツイッターで紹介したいとき、役に立つと思います。
このExtensionは以下の機能を持っています。
・画像の出力設定を切り替えられます。
・描画される情報を項目ごとに設定できます。
・画像サイズによってフォントサイズが自動で切り替わります。
追加したい機能があればリクエストしてください。
私に可能であれば対応します。
Version1.1
新しい機能を追加しました。 これにより、画像の周囲に余白を作成し、そのスペースにテキストを書き込むことができます。 これで、画像の重要な部分を隠さずに画像にテキストを追加できるようになりました。
Version1.2
カスタム フォント サイズを指定: ユーザーがテキストのカスタム フォント サイズを設定できるようにします。
直感的な改行: テキストを読みやすくするために改行を実装します。