Tutorial: Free Demo Spaces for SD Models on HuggingFace
Want to be able to test a model you've seen around that has a diffusers option on huggingface?
(Please note: This tutorial does not cover yoinking models that DONT have a diffusers option and making your own spaces, nor does it cover adding your own diffusers option to your model, that'll come sooner than later.)
Added file is a zip file with IMAGES and a PDF/DOCX of just the images, i may add the text version later on.
Join our Reddit: https://www.reddit.com/r/earthndusk/
This is fairly straight forward and should be easy enough to follow.
So your first thing is to go to https://huggingface.co - if anything you're likely not logged in (and yes sadly it stores cookies from both FIREFOX and chrome, and it logged me off mid uploading models to a repository - ugh i'm dumb)
When you're there, don't worry if you don't have an account, this tutorial is for both users and non users of HF. You'll have ways of finding what you need, and sometimes Civit users will post their HF links in their descriptions.
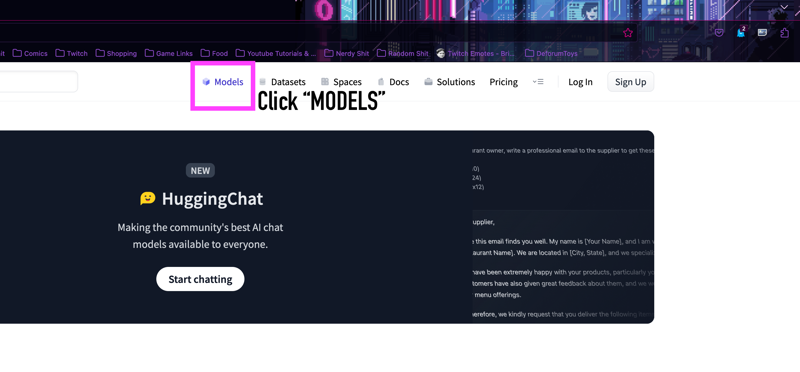
You'll LIKELY FIRST want to try clicking models. Don't worry, there's a way to find what you need it's not easy but there's some ways around this nightmare GitHub styled fuel.
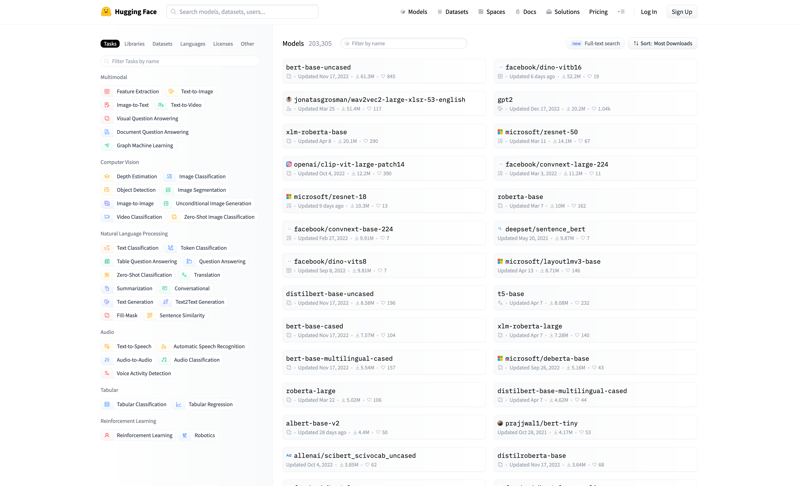
This is what it looks like when you first get to the models page, it's a little daunting because they offer more than just SD or Text to Image models.
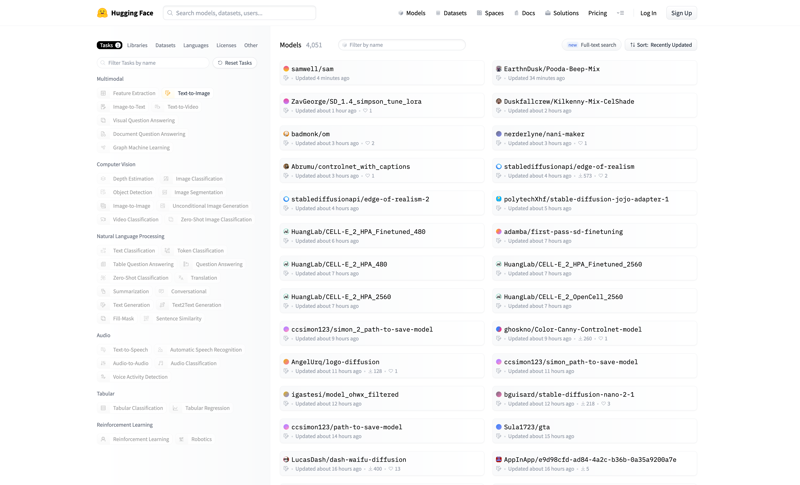
You're going to want to click TEXT TO IMAGE

Once you've clicked that (though you're allowed to browse the other sections my child just wait your turn! LOL) - you'll see the rest of the sections greyed out:

For this instance we've actually just clicked on our model for reference, but you have the choice of 1000s of different things Inclusive of Dreamshaper, Protogen & More!
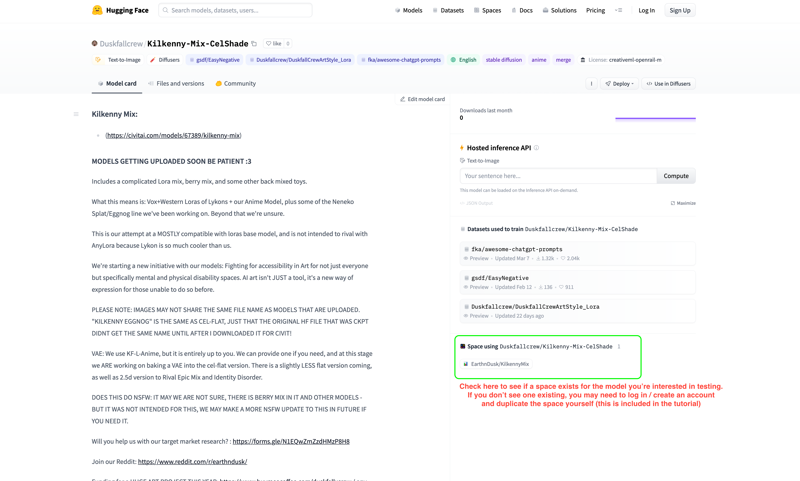
You will note the model card varies per space, and you have a choice of JUST testing it via the model card OR - there may be spaces available already.
If there's a space available you'll see it in the bottom right hand corner of your screen.
Warning: It MAY QUEUE up depending on the popularity, we will cover logging in and duplicating this.
Just for show this is what it looks like when I don't make tons of text on the screen for you.
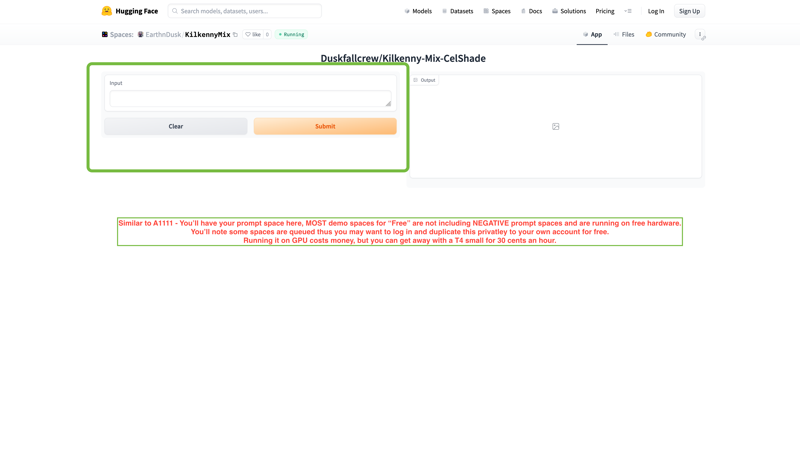
Also noting that since this is a FREE gradio based space, there is no negative prompt and it is limited by the FREE API that is included in the space. Again we'll let you know how to dupe this. privately.
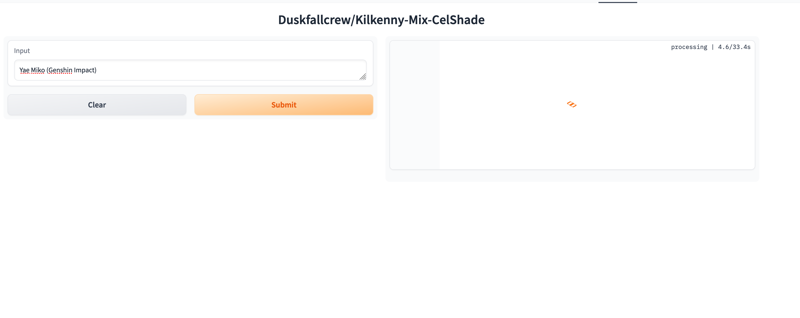
NOW! you can make PRETTY WAIFUS! (lol) - Or just y'now test it!
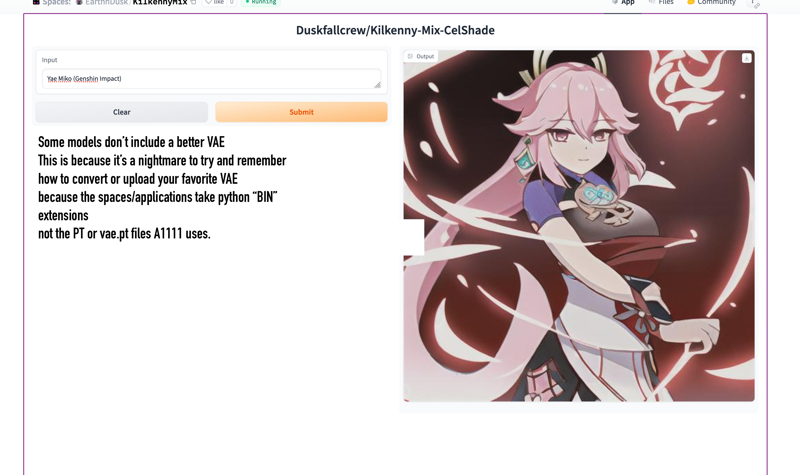
Yea so here's a REALLY BAD EXAMPLE because we haven't had the moment to get the correct VAE running - because even for a mid tier user like me you have to download the diffuser's VAE from the right space and replace it like a ninja before someone realizes you're vae-less. (It's not QUITE VAE-LESS it's just running on what's encoded in the model - and in this case none of mine are baked). SOME PEOPLE do have this fixed, one or two of ours ARE the right VAE, and Lykon makes baked VAE versions and adds them for demo spaces.
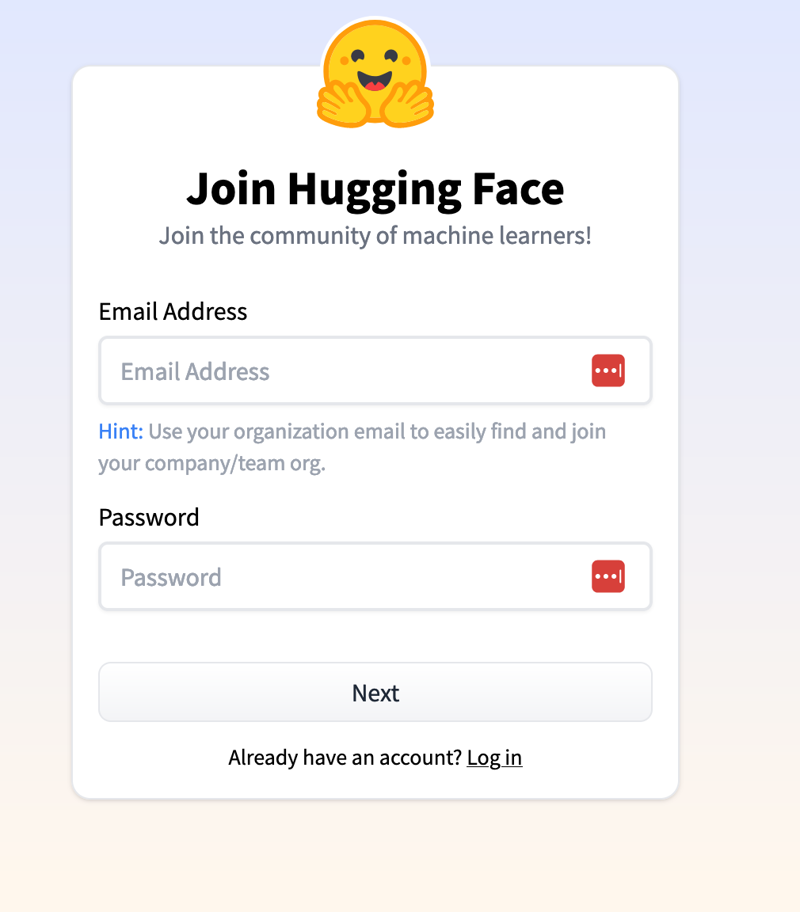
NOW FOR THE FUN PART: If you haven't got an account SIGN UP, because you'll need it for making tons of your own private duplicated spaces to test things.
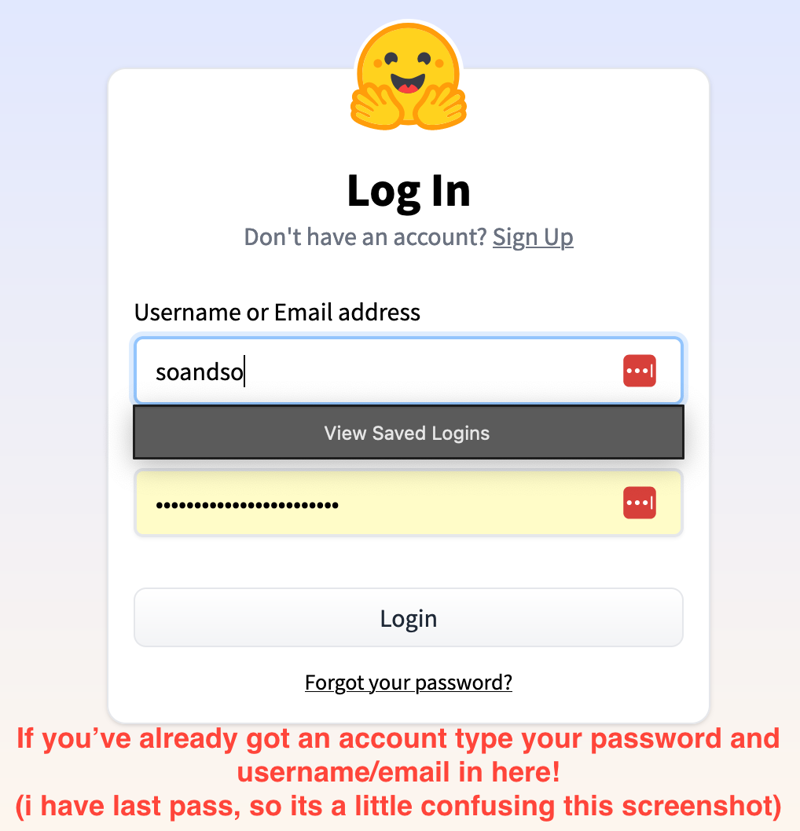
Again I use last pass, so it gets in the way - and I was trying not to doxx my email so I typed in the box. So if you've got an account or finished signing up - do log in. (WARNING: I USE DARK MODE SO COMING UP EVERYTHING IS IN DARK MODE)
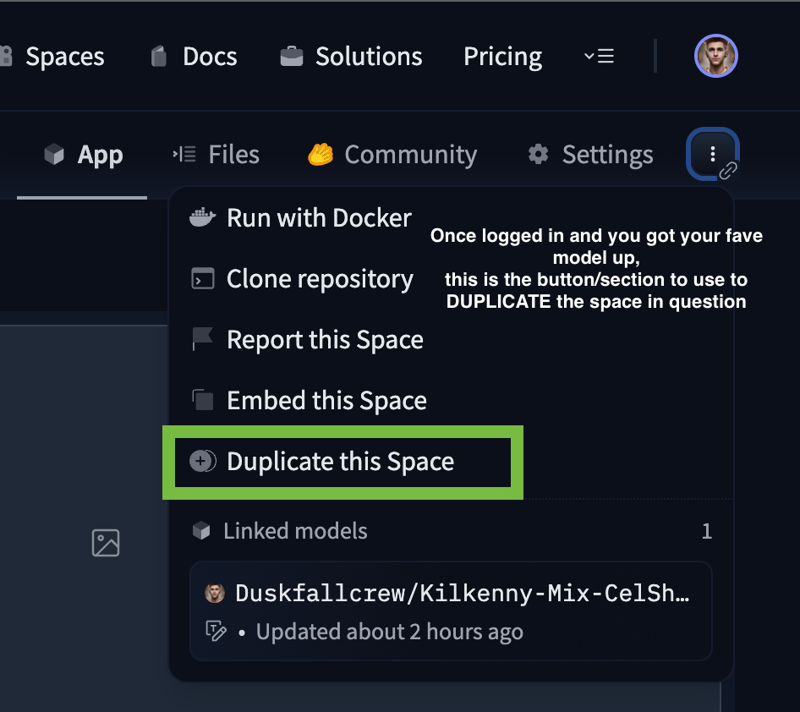
When you get to the space in question AGAIN you'll see the top right hand corner has a LINK/ATTACHEMENT button - kinda like a 2-3 dot hamburger menu with a chain link. "DUPLICATE THIS SPACE" is your option you're looking for. YOU CAN embed it randomly in an HTML site if you felt like it but i'm not covering any advanced options if i haven't tried it yet myself.

This is ROUGHLY WHAT IT WILL LOOK like, i'm not going to show you what it looks like while building because i'm not really in the mood to re-duplicate six of my model spaces LOL. You'll get a choice between any ORGANIZATIONS you've signed up for OR just your base profile, name the space what you want and if you WANT extra GPU GO BRR and wanna pay for it you have the option. You can do PUBLIC or PRIVATE for this and private just means you don't have to wait in the queue to make WAIFUS.
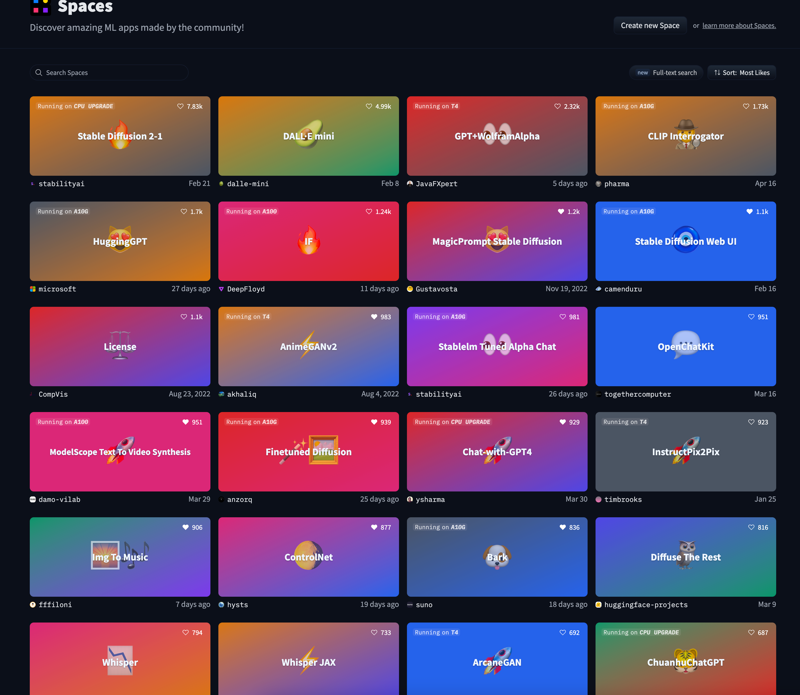
This is the fun playground, you get to see TONS of new things made every day inclusive of things from corporations using Huggingface. Not just interested in Waifus or fap material? (Kidding, it's also about art, and fun XD) - You can use Mubert, Riffusion or even see the latest in Text GPT models!
THEN YOU CAN EVEN DUPLICATE MOST OF THESE IN PRIVATE TOO!
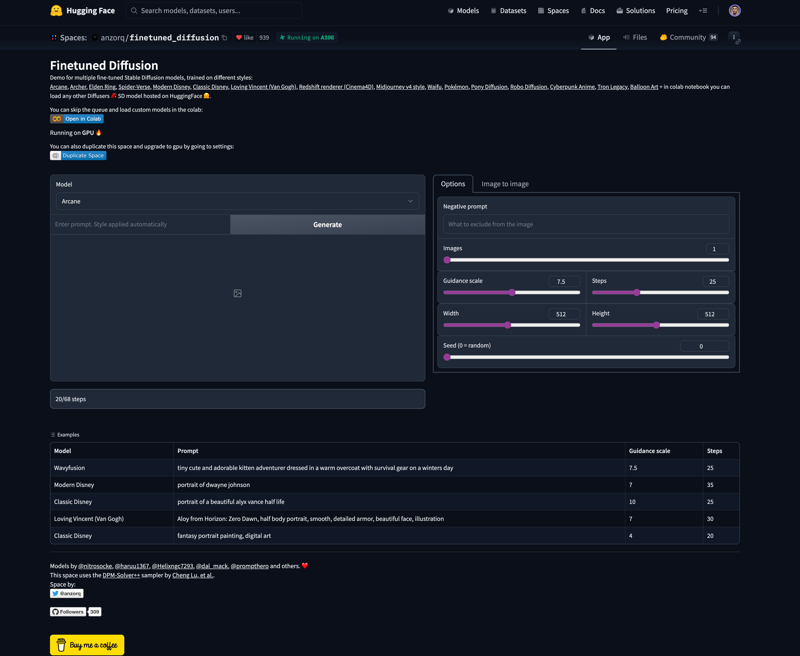
There ARE WEBUI like functionality spots with hardware paid for by either HF through grants OR via the user themselves. Duplicating these without paying for hardware breaks the spaces and is a no no and a bad annoying idea.
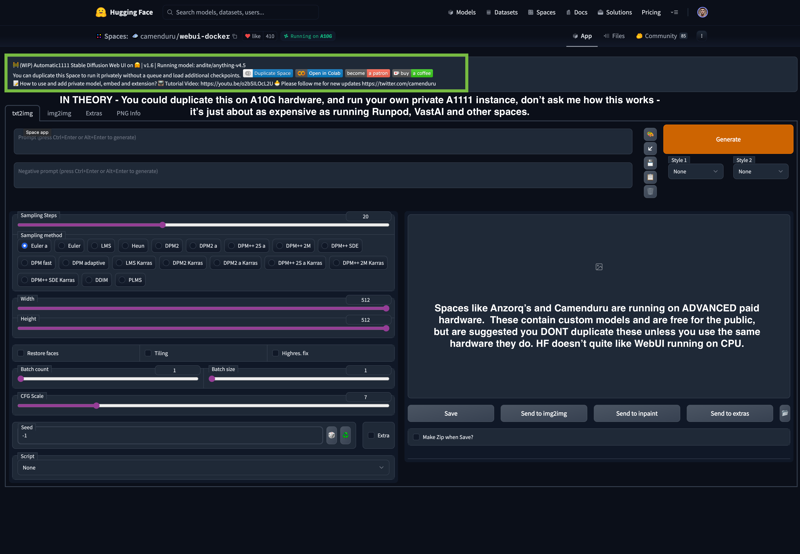
not that it's illegal to do so, but because a lot of these aren't coded to run on HF spaces without higher end hardware. If you're looking to run WEBUI free well, you know the deal Google hates freeloaders (and their paid users XD) - and finding free options these days is a NIGHTMARE.
If ya got any questions?
Will you help us with our target market research?: https://forms.gle/N1EQwZmZzdHMzP8H8
Join our Reddit: https://www.reddit.com/r/earthndusk/
:Funding for a HUGE ART PROJECT THIS YEAR:: https://www.buymeacoffee.com/duskfallxcrew / any chance you can spare a coffee or three? https://ko-fi.com/DUSKFALLcrew
:If you got requests, or concerns, We're still looking for beta testers: JOIN THE DISCORD AND DEMAND THINGS OF US:: https://discord.gg/Da7s8d3KJ7
:Listen to the music that we've made that goes with our art:: https://open.spotify.com/playlist/00R8x00YktB4u541imdSSf?si=b60d209385a74b38







