You will need ControlNet (I was using version 1.1.166) with a segmentation model. Optionally you will need some editing software. I will be using Photoshop but you can use whatever program you want.
Model: Counterfeit-V3.0, but it should work with most models.
Links
Counterfeit-V3.0 model: Counterfeit-V3.0 - v3.0 | Stable Diffusion Checkpoint | Civitai
VAE I used: civitai.com/models/23906/kl-f8-anime2-vae
EasyNegative embedding: civitai.com/models/7808/easynegative
ControlNet: github.com/lllyasviel/ControlNet
ControlNet models: huggingface.co/lllyasviel/ControlNet-v1-1/tree/main
How to install: ControlNET 1.1 - What you NEED to know!
For CLIP and VEA Settings add this to Settings -> User Interface -> Quicksettings List:
CLIP_stop_at_last_layers, sd_vae
1. Set up ControlNet and txt2img
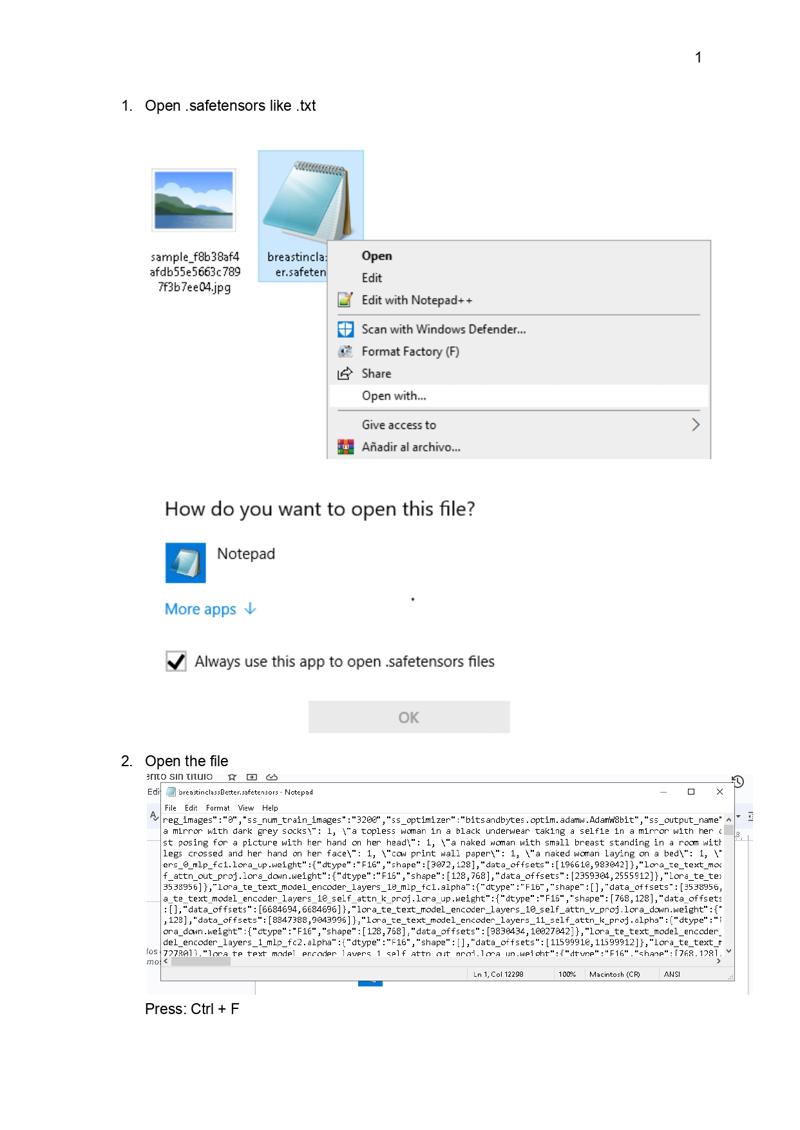
First we need to make segmentation image for ControlNet. To do this you can use an existing image from txt2img/Internet or draw it by yourself. Depending what angles or how many views you want to have it will look differently (other examples I made and tested are on the end of this post)
Drop your image and set Preprocessor to ‘seg_ufade20k’. Click Allow Preview, then click red explosion button. After it ends processing save this image with download button in the top right corner.
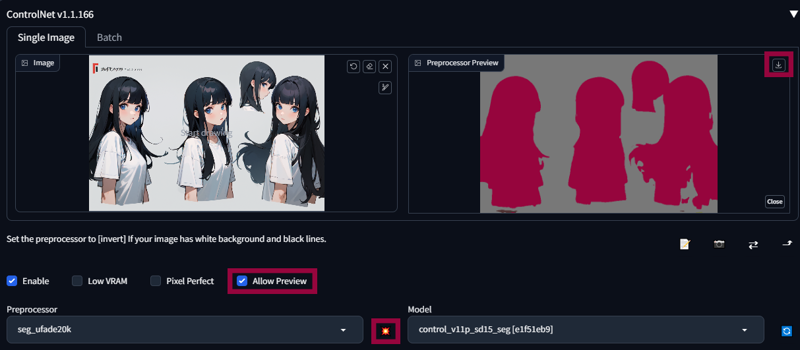
For some images you will need to clean it. After that, drop your clean image to ControlNet and set Preprocessor to ‘none’. Select ‘control_v11p_sd15_seg’ model and click ‘Enable’.
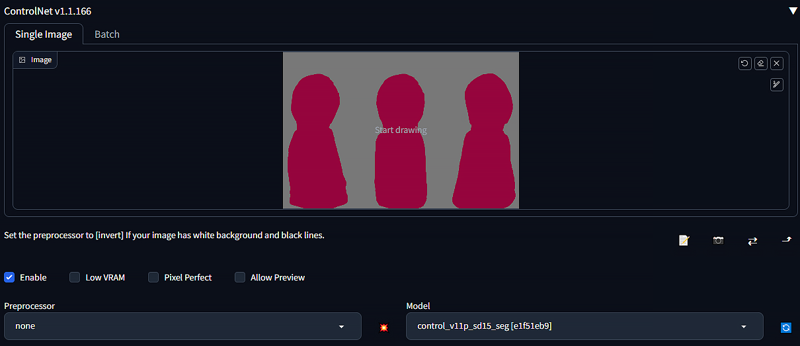
Colors: Red: #96053D, Grey: #787878.
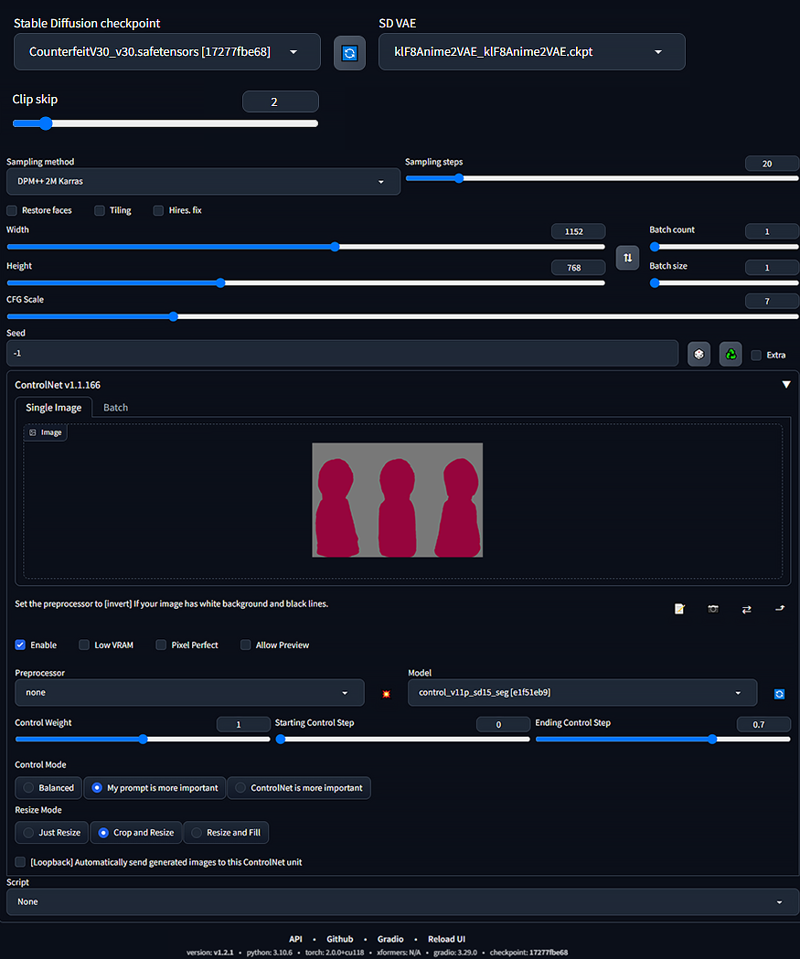
I suggest you set Control Mode to ‘My prompt is more important’ and Ending Control Steps to 0.6-0.9.
After that it’s time to set up txt2img. I suggest you use 3:2 ratio.
Resolution: 768x512 or higher if you have a good graphic card. I’m using 1152x768.
Higher resolution should give you better quality.
(These settings are just an example, feel free to play with it but I suggest you leave white background, simple background, reference sheet, from below, from above, multicolored background, multiple views, variations, mismatched clothes)
Prompt example:
Positive prompt: masterpiece, best quality, ultra-detailed, absurdres, 1girl, blue eyes, black hair, long hair, blunt bangs, detailed eyes, wide-eyed, eyelashes, looking at viewer, upper body, white background, simple background, reference sheet, standing, white t-shirt
Negative prompt: EasyNegative, monochrome, mismatched pupils, symbol-shaped pupils, heterochromia, multicolored eyes, no pupils, slit pupils, asymmetrical pupils, empty eyes, asymmetrical eyes, mismatched eyelashes, asymmetrical eyebrows, asymmetrical eye shading, two-tone hair, streaked hair, colored inner hair, multicolored hair, gradient hair, earrings, hair ornaments, boy, asymmetrical breasts, grabbing, text, from below, from above, multicolored background, multiple views, variations, mismatched clothes
Other settings are not that important - you can use whatever you want.
I used these settings:
2. Click Generate and take image you like most.
This is the image I’ve generated (seed: 3355877752):

Now it’s time to edit this image. (if you like your result you can skip this step)
Image after editing:

3. Set up img2img
Upload your image to img2img.
Copy settings from txt2img, but this time don’t use ControlNet.
I suggest you use higher resolution than txt2img but like before - if you don’t have good gpu just use 768x512. I’m using 1536x1024 here.
Change prompt.
Positive prompt: masterpiece, best quality, ultra-detailed, absurdres, 1girl, blue eyes, black hair, long hair, blunt bangs, detailed eyes, wide-eyed, eyelashes, looking at viewer, upper body, reference sheet, standing, white t-shirt, outdoors, blue sky, clouds, trees
Negative prompt: EasyNegative, monochrome, mismatched pupils, symbol-shaped pupils, heterochromia, multicolored eyes, no pupils, slit pupils, asymmetrical pupils, empty eyes, asymmetrical eyes, mismatched eyelashes, asymmetrical eyebrows, asymmetrical eye shading, two-tone hair, streaked hair, colored inner hair, multicolored hair, gradient hair, earrings, hair ornaments, boy, asymmetrical breasts, grabbing, text, from below, from above, multiple views, variations, mismatched clothes
Resize mode: ‘Resize and fill’, denoising strength: 0.4-0.65.
My settings:
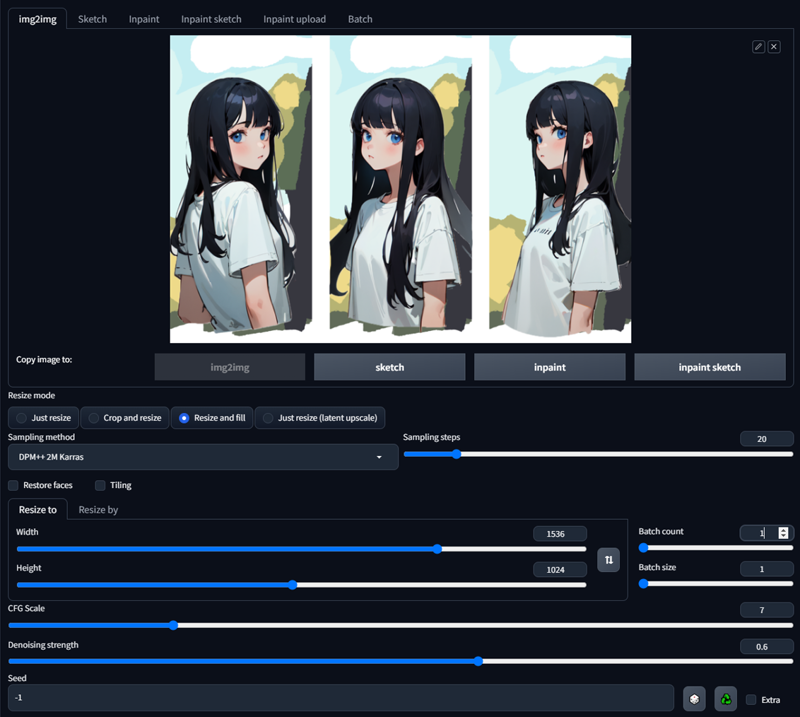
4. Generate until you get a good result
For more details you can take your output image, drop it to img2img and use it again with less denoising strength.
My output (seed: 2666038464):

___________________________________
Examples of different segmentation images: