ControlNet m2m script を利用すると動画のフレームをもとに画像を生成し、それを最後にまとめて GIF 動画として出力してくれます。(movie to movie)
勘違いが無いように書きますが、プロンプトだけで動画を生成することは出来ないということをご理解の上でお読みください。また、手間の割に出来上がるものは短い動画 1 つなので、不毛な時間を過ごした気分になれることは間違いないでしょう。
以下の内容は飽くまで一例・私個人のやり方であって、必ずこのようにやらなければならないということではありませんのでご留意ください。
私の他の投稿は ここ から見ることが出来ます
使用ソフトウェア
これらも私個人が勝手に使っているソフトです。代替となる方法やソフトウェアは世の中に山ほどあると思うので、個人に合ったものを選択してください。
各ソフトウェアのダウンロード、インストール、設定、使用方法などは取り上げません。ご自身で調べてください。 (そもそも解説できるだけの深い知識はありません)
手順
ざっくりとした手順は以下の通りです
ソースとなる動画を用意する
動画から切り出した 1 フレームだけの画像を ControlNet に読み込ませてテストする
プロンプトをテストする
Seed 値をテストする
ControlNet m2m script にソースとなる動画を読み込ませて出力する
1. ソースとなる動画を用意する
自分は OBS Studio を利用して 3D のアダルトゲームを録画しました。Blender から出力したアニメーション動画や、MMD の映像なども利用できると思います。可逆圧縮の utvideo コーデックを使って録画し、AVI コンテナに保存しています。
録画が済んだら aviutl にて必要な箇所だけ切り出します。
この時あまりにも長い区間を切り出してしまうと、出力にものすごく時間が掛かるので短い方が良いと思います。なので自分は 0.5 ~ 1 秒程度を目安としています。これを短いと感じる人も居るかもしれませんが、例えば 30fps の動画ではたったの 1 秒でも 30 枚の画像を生成することになります。
また、ループ再生してちゃんと連続的になるようにカットします。ループ再生に向かない内容なら、開始と終了にフェードイン/アウトのエフェクトなどを使用すると良いでしょう。ただ、この段階ではエフェクトは付けません。
被写体や背景が著しく変化するような場合やカメラが大きく動くような映像の場合、そもそも別のシーンとしてカットしてしまった方が良いと思います。これは後々プロンプトを書く時に、映っているものに合わせて書く必要があるからです。例えば被写体が 1 回転するような映像だった場合、正面が映っているフレームと背中が映っているフレームがあることになります。正面が映っているフレームは、みんな大好きな breasts などと書いておけばいいですが、背中が映っているのフレームを処理する際のプロンプトでは breasts は消して back などと書かなくてはならないでしょう。( backboob かもしれませんがw)
カットが済んだら x264 エンコーダを利用して mp4 形式にエンコードします。aviutl であれば x264guiEx プラグインがあると楽でしょう。
この時、x264 のオプションに --qp 0 を指定すると可逆圧縮 (無劣化) となります。エンコードによるノイズがソース動画に発生すると生成される画像に悪影響があったりするので、自分は可逆圧縮を行っています。
mp4 以外の形式のまま m2m script に動画を読み込ませると自動的に mp4 に変換される様ですが、この時にノイズが乗る可能性があるので自分でエンコードを行っています。
2. 動画から 1 フレームだけ切り出した画像を ControlNet に読み込ませてテストする
動画を m2m script に読み込ませる前に、動画から画像を切り出してテスト画像とし、それを使ってテストを行います。
画像を切り出す方法はいくらでもありますが、自分は FFMpeg の連番出力機能で全フレームを画像化しています。(たまに他のフレームでもテストしたくなることがあるので)
以下は FFMpeg で動画から連番画像を出力するコマンド例です
ffmpeg -hide_banner -i "src.mp4" -ss "0:00" -f "image2" -startnumber 1 "%04d.png"
2-1. プロンプトをテストする
いきなり動画を m2m に読み込ませてテキトーなプロンプトやパラメータで出力してもまず良い動画にはなりません。
先ほど作ったテスト画像を使って色々なプロンプトや ControlNet のパラメータで出力を試します。この時はランダムな Seed でテストします。
ControlNet のどのモデルを使ったりパラメータを調整するかは、どのようなソース動画かによって変わりますが、自分は lineart や tile_resample を weight 0.5 ずつくらいで使うことが多いです。
新しく実装された reference_only 用の画像を用意すれば、かなりイメージに近づけやすくなると思います。
以下はプロンプトによる違いの例です (ControlNet のモデルとパラメータは同じです)



1 枚目はソース画像、2 枚目はクオリティのみ、3 枚目はクオリティと描画される (べき) ものも書き込んだプロンプトです。
2 枚目のプロンプトは以下です
(masterpiece:1.2, best quality)
Negative prompt: (worst quality, low quality:1.4), EasyNegative
3枚目のプロンプトは以下です
thigh sex, clothed female nude male, simple background, black background, sad face young girl, silver short hair, diagonal bangs, blue eyes, green sportswear, covered nipples, panties aside, evil simle ugly man, frottage, grinding, penis, bald, (beard:0.8), (masterpiece:1.2), (best quality)
Negative prompt: (worst quality), (low quality:1.4), EasyNegative, (haze:1.4), (steam:1.4), (breath:1.4), text, subtitled, watermark, (logo:1.4), signature, username, artist name, title, subtitle, date stamp, header, footer, (clothes writing:1.4), tag, name tag, green skin
元となる動画があるからプロンプトはテキトーで良い、ということは全く無く、2 枚目の画像の様にそもそも服の色が違ったり、男性の性器が消えてしまったりします。(太ももコキの動画なのにチンチン消されたらたまらないですね)
こういう大きい違いが生まれる部分はプロンプトに書き込んで描いてもらうようにします。
元の動画に存在しない物をプロンプトで生成したりもできますが、全フレームで安定して同じように描いてくれることはほぼ無いです。服の色を変える、程度のことならできますが、これも模様が出てしまったり、色合いが変わったりして安定しません。
そしてプロンプトを書いてみたものの、3 枚目は AI が謎に気を利かせてしまい、見えないはずの女性の右手が描かれています。こういった場合はプロンプトで消すことは難しいので、次の Seed 値のテストに入ります。(ガチャ)
2-2. Seed 値をテストする
大体どの Seed 値でも同じような傾向で出力されるようになってきたら、プロンプトを固定します。
プロンプトは変えずに Seed 値だけを変えて複数の画像を出力し、その中に気に入ったものがあればその画像の Seed 値で固定します。
気に入ったものがいつまでも出てこない場合は、プロンプトに過不足があるか、そもそも細かいところにこだわり過ぎているかのどちらかです。
以下は先ほどの 3 枚目の画像と同じプロンプトで、Seed 値が違う画像の例です。


この 2 つの Seed 値は服の色が変わってしまっていて違いが目立つので採用できませんが、このような大きい違いで無ければあまり気にしなくても大丈夫だと思います。
100% 完璧で細部まで理想通りの画像を出力してくれることは無いので、ある程度の妥協は必要です。
例えば 30fps の動画の 1 コマはたったの 0.033...秒しか表示されません。
1 コマの出来が良いに越したことはないですが、前後のフレームとの違いが大きい方が最終的に動画として見た時の違和感になると思っています。
この違和感を減らすために Seed 値を固定してしまいます。
3. ControlNet m2m script に動画を読み込ませて出力する
ControlNet がインストールされていれば Script の一覧の中に controlnet m2m があります。
このスクリプトはシンプルで、
スクリプト欄で controlnet m2m を選ぶ
動画を枠内にドラッグアンドドロップする
Duration を設定する
たったこれだけで使うことが出来ます。
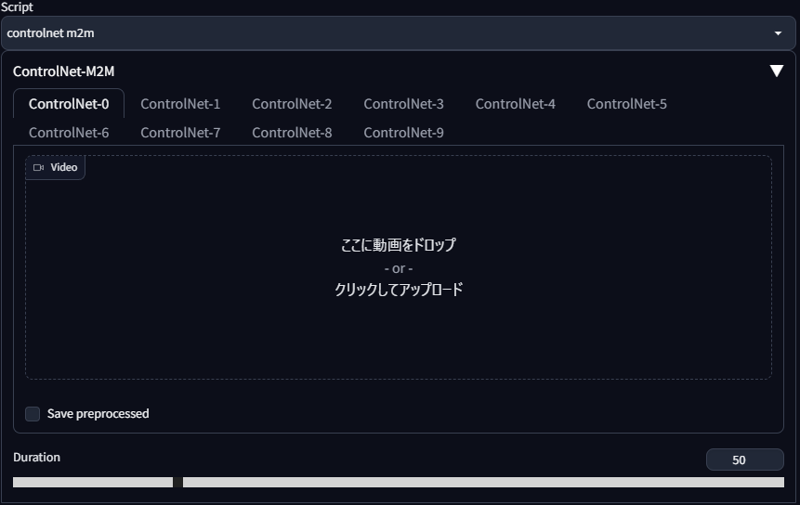
ここで 1. でエンコードして用意した mp4 形式のソース動画を m2m script に読み込ませます。
Duration には「1 枚のフレームが表示される時間」を指定します。(ミリ秒?)
Generate ボタンを押して出力を開始すると各フレームが全て画像として出力され、全フレームの処理が終わると GIF 動画が出来上がります。
その他
出来上がった動画 (連番画像) にエフェクト等を入れたり編集を行いたい場合
ffmpeg を使用すると、連番画像から動画を作ることが出来ます。
m2m script は GIF を作りますが、同時に連番画像も出力してくれます。その連番画像から AVI の動画を作成します。
以下は連番画像を AVI 形式の動画に変換するコマンド例です
ffmpeg -hide_banner -framerate "30" -i "%05d-<SEED_VALUE>.png" -vcodec "utvideo" -video_size "512x512" -pix_fmt "yuv444p" -r "30" "output.avi"
-i "%05d-<SEED_VALUE>.png" の <SEED_VALUE> は自分が出力に使用した Seed 値に置き換えます。山括弧 (<と>)は不要です。
-framerate、-r で任意のフレームレートを指定できます。-video_size は任意の解像度を WxH の形式で指定できます。
AVI 形式の動画に変換してしまえば動画編集ソフトで自由に編集できます。
編集した動画を GIF にしたい
ffmpeg を使用すると (ry
ffmpeg -hide_banner -i "src.avi" -filter_complex "[0:v] fps=30,scale=512:512,split [a][b];[a] palettegen [p];[b][p] paletteuse=dither=floyd_steinberg" "output.gif"
ディザリングのアルゴリズムは他にもあるので試してみて良いと思う。見た目やファイルサイズが微妙に変わります。
以下はディザリングのアルゴリズムのリストを表示するコマンド例です
ffmpeg -hide_banner -h filter=paletteuse
投稿にあった質問への回答
Q. i2i を使っているのか
A. 現状使ったことが無いが、フレーム単位で細かい修正が必要ならアリなのかもしれない。ものすごい手間だとは思うが。
Q. 背景を消しているのか
A. 現状消していない。元々シンプルな黒背景の動画をソースにしている。もし背景を消そうと思ったら高価で高性能な After Effects の「ロトブラシ」の様な機能が必要になると思う。それか GIMP で全フレーム (!) の背景を地道に消していくか・・・。
Q. この記事を英訳してほしい
A. 無理。中学英語ですら怪しい自分には英訳は不可能。DeepL や ChatGPT などを使うか、日本語に詳しい人物でも探して読んでもらってください。
そもそも日本語でこのページを書くのですら自分には何の得にもならない行為なのに、輪を掛けて英訳するモチベーションなどあるわけもなく。
EF EPI によると日本人の英語理解度は 111 か国中 80 位 だったそう。(2022年)
能力レベルとしては「低い」で、アジアだけで見ても 24 か国中 14 位と低い。
https://www.ef.com/wwen/epi/regions/asia/japan/
https://www.efjapan.co.jp/epi/






