Believer Devil
файл на civitaiстраница на civitaiSHA256: AE68B93C7FBD1F7693129EB2A006371BFFF1D99C7B1E7A7FFEC17637B8D76C2E
This is simply a text file to be placed in your LORA folder alongside SAO - Sword Art Online LORA
With 33 different models I thought it would be helpful to save everyone the trouble of creating their own since I am the creator and can't always remember them all.

They can generate multiple subjects. Each subject has its own prompt.
They require some custom nodes to function properly, mostly to automate out or simplify some of the tediousness that comes with setting up these things. Please check the About this version section for each workflow for required custom nodes
There are three methods for multiple subjects included so far:
Limits the areas affected by each prompt to just a portion of the image
Includes ControlNet and unCLIP (enabled by switching node connections)
From my testing, this generally does better than Noisy Latent Composition
Generates each prompt on a separate image for a few steps (eg. 4/20) so that only rough outlines of major elements get created, then combines them together and does the remaining steps with Latent Couple
This is an """attempt""" at generating 2 characters interacting with each other, while retaining a high degree of control over their looks, without using ControlNets. As you may expect, it's quite unreliable.
We do this by generating the first few steps (eg. 6/30) on a single prompt encompassing the whole image that describes what sort of interaction we want to achieve (+background and perspective, common features of both characters help too).
Then, for the remaining steps in the second KSampler, we add two more prompts, one for each character, limited to the area where we "expect" (guess) they'll appear, so mostly just the left half/right half of the image with some overlap.
I'm not gonna lie, the results and consistency aren't great. If you want to try it, some settings to fiddle around with would be at which step the KSampler should change, the amount of overlap between character prompts and prompt strengths. From my testing, the closest interaction I've been able to get out of this was a kiss, I've tried to go for a hug but with no luck.
The higher the step that you switch KSamplers at, the more consistently you'll get the desired interaction, but you'll lose out on the character prompts (I've been going between 20-35% of total steps). You may be able to offset this a bit by increasing character prompt strengths

A simple ComfyUI plugin for images grid (X/Y Plot)

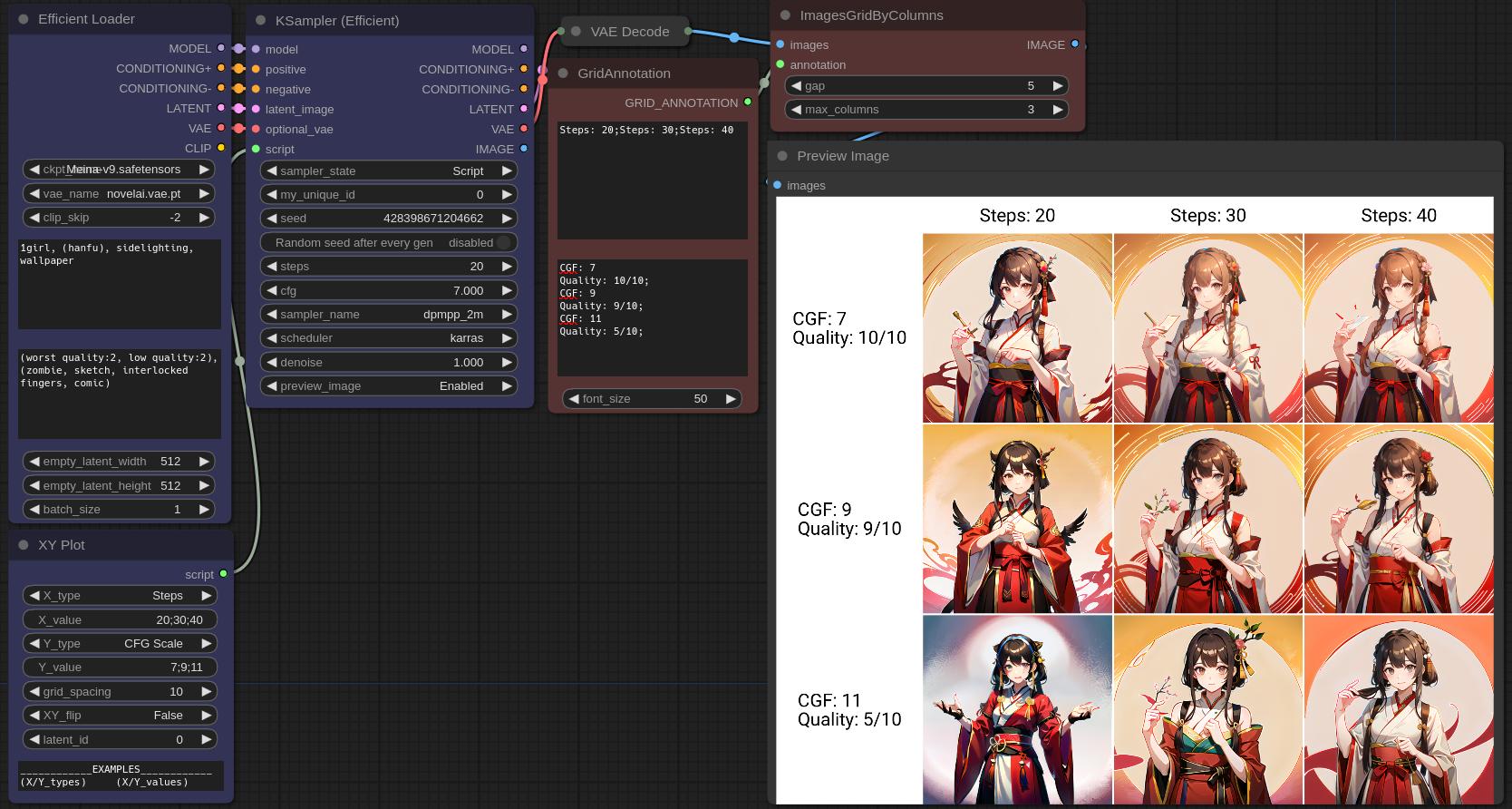


Workflows: https://github.com/LEv145/images-grid-comfy-plugin/tree/main/workflows
Download the latest stable release: https://github.com/LEv145/images-grid-comfy-plugin/archive/refs/heads/main.zip
Unpack the node to custom_nodes, for example in a folder custom_nodes/ImagesGrid/

"Super Easy AI Installer Tool" is a user-friendly application that simplifies the installation process of AI-related repositories for users. The tool is designed to provide an easy-to-use solution for accessing and installing AI repositories with minimal technical hassle to none the tool will automatically handle the installation process, making it easier for users to access and use AI tools.
For Windows 10+ and Nvidia GPU-based cards
Don't forget to leave a like/star.
For more Info:
https://github.com/diStyApps/seait
Please note that Virustotal and other antivirus programs may give a false positive when running this app. This is due the use Pyinstaller to convert the python file EXE, which can sometimes trigger false positives even for the simpler scripts which is a known issue
Unfortunately, I don't have the time to handle these false positives. However, please rest assured that the code is transparent on https://github.com/diStyApps/seait
I would rather add features and more AI tools at this stage of development.
Source: https://github.com/pyinstaller/pyinstaller/issues/6754
Download the "Super Easy AI Installer Tool" at your own discretion.
Multi-language support [x]
More AI-related repos [x]
Set custom project path [x]
Custom arguments [x]
Pre installed auto1111 version [ ]
App updater [ ]
Remembering arguments [ ]
Maybe arguments profiles [ ]
Better event handling [ ]
Fully standalone version no python or git needed [ ]
Support
https://www.patreon.com/distyx
https://coindrop.to/disty

This is a template to be used with my templated animation script and my vaginal depth model. You need both!
note: you need the model at https://civitai.com/models/48341/vaginal-depth-concept for the animation to be smooth
install the script, over at https://civitai.com/models/42798/templated-animation-script
to install the script just extract the py file to your webui/scripts directory and restart the webui
download this file, it's a zip, with a txt file in it
extract the txt file
open the webui
scroll to the bottom of the webui on the txt2img tab, select 'Prompts from templated file or textbox with GIF generation'
optional: use the generation data, from one of the gifs I set as a sample if you want to generate that exact gif,
set 'frame duration' to your preference, recommended 100, for 10fps
in 'replacement text' enter 'prompt' (NOTE: do not forget to do this or the webui will hang)
option: you can either copy past or upload the file
to copy paste, simply open the txt file from step 3, ctrl a, ctrl c, that file, and ctrl v it into the 'List of prompt inputs' box
OR: you can click on 'click to upload' and select the txt file
enter the details you want into the prompt box, ex, long hair, red hair, black eyes, happy, happy sex, medium breasts, completely nude, mature female, (thigh grab:1.3), grab, freckles, (arms behind back:1.1), <lora:vaginalDepthConcept_v1:0.7>,
click generate! wait for it to finish, might take 20 seconds, might take 20 minutes, depends on your hardware, but at the end, there should be a sexy scene animated with the character you described in your prompt box
For step 9 above, note that the lora vaginalDepthConcept_v1 was invoked in the prompt, you need that for the animations to be smooth. You can find it at https://civitai.com/models/48341/vaginal-depth-concept
Also! Style loras help a lot for reducing flicker and making the frames more consistent.


Ksampler (Efficient)
A modded KSampler with the ability to preview and output images.
Re-outputs key inputs which helps promote a cleaner and more streamlined workflow look for ComfyUI.
Can force hold all of its outputs without regenerating by setting its state to "Hold".
Simplifies the comparison of settings by generating clear and concise image plots.
Efficient Loader
A combination of common initialization nodes.
XY Plot
A node that allows users to specify parameters for the KSampler (Efficient) to plot on a grid.
Image Overlay
Node that allows for flexible image overlaying.
Evaluate Integers
3 integer input node that gives the user ability to write their own python expression for a INT/FLOAT type output.
Evaluate Strings
3 string input node that

ComfyUI is an advanced node based UI utilizing Stable Diffusion. It allows you to create customized workflows such as image post processing, or conversions.
A node suite for ComfyUI with many new nodes, such as image processing, text processing, and more.
Share Workflows to the /workflows/ directory. Preferably embedded PNGs with workflows, but JSON is OK too. You can use this tool to add a workflow to a PNG file easily
ASCII is deprecated. The new preferred method of text node output is TEXT. This is a change from ASCII so that it is more clear what data is being passed.
The was_suit_config.json will automatically set use_legacy_ascii_text to true for a transition period. You can enable TEXT output by setting use_legacy_ascii_text to false
BLIP Analyze Image: Get a text caption from a image, or interrogate the image with a question.
Model will download automatically from default URL, but you can point the download to another location/caption model in was_suite_config
Models will be stored in ComfyUI/models/blip/checkpoints/
SAM Model Loader: Load a SAM Segmentation model
SAM Parameters: Define your SAM parameters for segmentation of a image
SAM Parameters Combine: Combine SAM parameters
SAM Image Mask: SAM image masking
Image Bounds: Bounds a image
Inset Image Bounds: Inset a image bounds
Bounded Image Blend: Blend bounds image
Bounded Image Blend with Mask: Blend a bounds image by mask
Bounded Image Crop: Crop a bounds image
Bounded Image Crop with Mask: Crop a bounds image by mask
CLIPTextEncode (NSP): Parse Noodle Soup Prompts
Conditioning Input Switch: Switch between two conditioning inputs.
Constant Number
Dictionary to Console: Print a dictionary input to the console
Image Analyze
Black White Levels
RGB Levels
Depends on matplotlib, will attempt to install on first run
Image Blank: Create a blank image in any color
Image Blend by Mask: Blend two images by a mask
Image Blend: Blend two images by opacity
Image Blending Mode: Blend two images by various blending modes
Image Bloom Filter: Apply a high-pass based bloom filter
Image Canny Filter: Apply a canny filter to a image
Image Chromatic Aberration: Apply chromatic aberration lens effect to a image like in sci-fi films, movie theaters, and video games
Image Color Palette
Generate a color palette based on the input image.
Depends on scikit-learn, will attempt to install on first run.
Supports color range of 8-256
Utilizes font in ./res/ unless unavailable, then it will utilize internal better then nothing font.
Image Crop Face: Crop a face out of a image
Limitations:
Sometimes no faces are found in badly generated images, or faces at angles
Sometimes face crop is black, this is because the padding is too large and intersected with the image edge. Use a smaller padding size.
face_recognition mode sometimes finds random things as faces. It also requires a [CUDA] GPU.
Only detects one face. This is a design choice to make it's use easy.
Image Paste Face Crop: Paste face crop back on a image at it's original location and size
Features a better blending funciton than GFPGAN/CodeFormer so there shouldn't be visible seams, and coupled with Diffusion Result, looks better than GFPGAN/CodeFormer.
Image Dragan Photography Filter: Apply a Andrzej Dragan photography style to a image
Image Edge Detection Filter: Detect edges in a image
Image Film Grain: Apply film grain to a image
Image Filter Adjustments: Apply various image adjustments to a image
Image Flip: Flip a image horizontal, or vertical
Image Gradient Map: Apply a gradient map to a image
Image Generate Gradient: Generate a gradient map with desired stops and colors
Image High Pass Filter: Apply a high frequency pass to the image returning the details
Image History Loader: Load images from history based on the Load Image Batch node. Can define max history in config file. (requires restart to show last sessions files at this time)
Image Input Switch: Switch between two image inputs
Image Levels Adjustment: Adjust the levels of a image
Image Load: Load a image from any path on the system, or a url starting with http
Image Median Filter: Apply a median filter to a image, such as to smooth out details in surfaces
Image Mix RGB Channels: Mix together RGB channels into a single iamge
Image Monitor Effects Filter: Apply various monitor effects to a image
Digital Distortion
A digital breakup distortion effect
Signal Distortion
A analog signal distortion effect on vertical bands like a CRT monitor
TV Distortion
A TV scanline and bleed distortion effect
Image Nova Filter: A image that uses a sinus frequency to break apart a image into RGB frequencies
Image Perlin Noise Filter
Create perlin noise with pythonperlin module. Trust me, better then my implementations that took minutes...
Image Remove Background (Alpha): Remove the background from a image by threshold and tolerance.
Image Remove Color: Remove a color from a image and replace it with another
Image Resize
Image Rotate: Rotate an image
Image Save: A save image node with format support and path support. (Bug: Doesn't display image
Image Seamless Texture: Create a seamless texture out of a image with optional tiling
Image Select Channel: Select a single channel of an RGB image
Image Select Color: Return the select image only on a black canvas
Image Shadows and Highlights: Adjust the shadows and highlights of an image
Image Size to Number: Get the width and height of an input image to use with Number nodes.
Image Stitch: Stitch images together on different sides with optional feathering blending between them.
Image Style Filter: Style a image with Pilgram instragram-like filters
Depends on pilgram module
Image Threshold: Return the desired threshold range of a image
Image Transpose
Image fDOF Filter: Apply a fake depth of field effect to an image
Image to Latent Mask: Convert a image into a latent mask
Image Voronoi Noise Filter
A custom implementation of the worley voronoi noise diagram
Input Switch (Disable until * wildcard fix)
KSampler (WAS): A sampler that accepts a seed as a node inpu
Load Text File
Now supports outputting a dictionary named after the file, or custom input.
The dictionary contains a list of all lines in the file.
Load Batch Images
Increment images in a folder, or fetch a single image out of a batch.
Will reset it's place if the path, or pattern is changed.
pattern is a glob that allows you to do things like **/* to get all files in the directory and subdirectory or things like *.jpg to select only JPEG images in the directory specified.
Latent Noise Injection: Inject latent noise into a latent image
Latent Size to Number: Latent sizes in tensor width/height
Latent Upscale by Factor: Upscale a latent image by a factor
Latent Input Switch: Switch between two latent inputs
Logic Boolean: A simple 1 or 0 output to use with logic
MiDaS Depth Approximation: Produce a depth approximation of a single image input
MiDaS Mask Image: Mask a input image using MiDaS with a desired color
Number Operation
Number to Seed
Number to Float
Number Input Switch: Switch between two number inputs
Number Input Condition: Compare between two inputs or against the A input
Number to Int
Number to String
Number to Text
Random Number
Save Text File: Save a text string to a file
Seed: Return a seed
Tensor Batch to Image: Select a single image out of a latent batch for post processing with filters
Text Add Tokens: Add custom tokens to parse in filenames or other text.
Text Add Token by Input: Add custom token by inputs representing single single line name and value of the token
Text Concatenate: Merge two strings
Text Dictionary Update: Merge two dictionaries
Text File History: Show previously opened text files (requires restart to show last sessions files at this time)
Text Find and Replace: Find and replace a substring in a string
Text Find and Replace by Dictionary: Replace substrings in a ASCII text input with a dictionary.
The dictionary keys are used as the key to replace, and the list of lines it contains chosen at random based on the seed.
Text Input Switch: Switch between two text inputs
Text Multiline: Write a multiline text string
Text Parse A1111 Embeddings: Convert embeddings filenames in your prompts to embedding:[filename]] format based on your /ComfyUI/models/embeddings/ files.
Text Parse Noodle Soup Prompts: Parse NSP in a text input
Text Parse Tokens: Parse custom tokens in text.
Text Random Line: Select a random line from a text input string
Text String: Write a single line text string value
Text to Conditioning: Convert a text string to conditioning.
True Random.org Number Generator: Generate a truly random number online from atmospheric noise with Random.org
Text tokens can be used in the Save Text File and Save Image nodes. You can also add your own custom tokens with the Text Add Tokens node.
The token name can be anything excluding the : character to define your token. It can also be simple Regular Expressions.
[time]
The current system microtime
[time(format_code)]
The current system time in human readable format. Utilizing datetime formatting
Example: [hostname]_[time]__[time(%Y-%m-%d__%I-%M%p)] would output: SKYNET-MASTER_1680897261__2023-04-07__07-54PM
[hostname]
The hostname of the system executing ComfyUI
[user]
The user that is executing ComfyUI
When using the latest builds of WAS Node Suite a was_suite_config.json file will be generated (if it doesn't exist). In this file you can setup a A1111 styles import.
Run ComfyUI to generate the new /custom-nodes/was-node-suite-comfyui/was_Suite_config.json file.
Open the was_suite_config.json file with a text editor.
Replace the webui_styles value from None to the path of your A1111 styles file called styles.csv. Be sure to use double backslashes for Windows paths.
Example C:\\python\\stable-diffusion-webui\\styles.csv
Restart ComfyUI
Select a style with the Prompt Styles Node.
The first ASCII output is your positive prompt, and the second ASCII output is your negative prompt.
You can set webui_styles_persistent_update to true to update the WAS Node Suite styles from WebUI every start of ComfyUI
If you're running on Linux, or non-admin account on windows you'll want to ensure /ComfyUI/custom_nodes, was-node-suite-comfyui, and WAS_Node_Suite.py has write permissions.
Navigate to your /ComfyUI/custom_nodes/ folder
git clone https://github.com/WASasquatch/was-node-suite-comfyui/
Start ComfyUI
WAS Suite should uninstall legacy nodes automatically for you.
Tools will be located in the WAS Suite menu.
If you're running on Linux, or non-admin account on windows you'll want to ensure /ComfyUI/custom_nodes, and WAS_Node_Suite.py has write permissions.
Download WAS_Node_Suite.py
Move the file to your /ComfyUI/custom_nodes/ folder
Start, or Restart ComfyUI
WAS Suite should uninstall legacy nodes automatically for you.
Tools will be located in the WAS Suite menu.
This method will not install the resources required for Image Crop Face node, and you'll have to download the ./res/ folder yourself.
Create a new cell and add the following code, then run the cell. You may need to edit the path to your custom_nodes folder.
!git clone https://github.com/WASasquatch/was-node-suite-comfyui /content/ComfyUI/custom_nodes/was-node-suite-comfyui
Restart Colab Runtime (don't disconnect)
Tools will be located in the WAS Suite menu.
WAS Node Suite is designed to download dependencies on it's own as needed, but what it depends on can be installed manually before use to prevent any script issues.
In the WAS Node base folder you can run /path/to/ComfyUI/python_embeded/python.exe -m pip install -r requirements.txt from your command prompt or terminal, though it is preferred that you install with with git clone https://github.com/WASasquatch/was-node-suite-comfyui/

Since Ooga denied my Pull request on GitHub after implementing the code I gave them a week ago in another PR. I am adding the script here I am sure they will take the rest of the code I made in a week or two and deny me as contributor like they did b4. People can be cruel and ruthless; I won't be focusing on this any longer.
but here it is if you want to try
Features I added:
Hi-res fix,
Denoising strength slider,
Batch size Batch count
Select all available Models dropdown.
Select all available Up-scalers,
Select all available Samplers,
Slider for size goes from 256 to 1024
Interactive mode keywords ("SD prompt" / "SD prompt of")
Saves metadata onto png.
Saves generation data to txt file.

Hi Sofia's images are generated with AI but they are based on photos of my friend of the same name sofia mendoza she has instagram and I have her permission for the images if you like it comment and follow her on her instagram page I leave it here and in the images that I will upload of her


comfy_translation_node
Updated --2023 04 24
There is no change in the update function, only a small change has been made to adjust the grouping of nodes and put them into xww-tran. If you have downloaded them before, you do not need to update them. If you want to update them, if you use openIE.txt, please first backup openIE.txt and then update it. If you don't overwrite comfy_translation_node directly, you'll be fine
Gratitude model:https://civitai.com/models/10415/3-guofeng3
For more details, please visit:https://github.com/laojingwei/comfy_translation_node
Description
can be used on ComfyUI interface node for translation, chinese-english translation, translation youdao and Google API support, a variety of options for your choice;
CN2EN: Support: translation api switch, whether to open translation, Chinese-English switch, embeddings selection, embeddings weight adjustment;
Tweak Keywords CN2EN: You can tweak the translated content, making it more flexible to tweak your keywords
Download
git clone git clone https://github.com/laojingwei/comfy_translation_node.git
ZIP download
Position installation and operation before use
Place the downloaded folder comfy_translation_node under ComfyUI\custom_nodes
If you want to start ComfyUI is used when you want the browser (just want to use the default browser can skip this step), you can edit openIE. TXT (path: PATH field in ComfyUI\custom_nodes\comfy_translation_node\openIE.txt), add the corresponding browser.exe execution file path to it, for example: PATH="C:\Program Files (x86)\Microsoft\Edge\Application\msedge.exe", other fields (*PATHOLD, SAVE*) never move, no matter what value they are do not change! If the ComfyUI code update fails, then you need to reset the other two fields to *PATHOLD=""* and *SAVE="FALSE"*
Go back to the ComfyUI update folder ComfyUI_windows_portable\update and execute the three files in order. Because this plugin requires the latest code ComfyUI, not update can't use, if you have is the latest (2023-04-15) have updated after you can skip this step
Go to the root directory and double-click run_nvidia_gpu.bat (or run_cpu.bat) to start ComfyUI. Note that if you did step 2 above, you will need to close the ComfyUI launcher and start again, because the first startup only initialized the browser path, which cannot be read. You will need to start again to open the browser you want. In the future, as long as you do not update the ComfyUI code, you will be able to open your browser every time. If you have an update later, you need to update the code twice before the service takes effect
Instructions for use
Node addition method: You can find utils by double-clicking into search and output related words or right-click to find utils and click in to search. Both of these nodes can be directly connected to the Text of CLIP Text Encode. CLIP Text Encode accepts text entry, and Text entry can be right-click on CLIP Text Encode. Find the Convert text to input, select it and the text entry will appear on the left side. (This is very important because many nodes can open the text entry in this way.)
CLIP Text Encode CN2EN
Text input field: Enter keywords
"language": 'AUTO' will not be translated, the original text will be output, 'CN' will be translated into Chinese (note that due to the translation api, please ensure that it is pure English before being translated into Chinese), 'EN' will be translated into English (Chinese and English can be mixed)
"transAPI": 'YOUDAO' uses Youdao api to translate,'GOOGLE' uses Google api to translate (Google call time is slow, generally about 2 seconds, sometimes will call failure, it is recommended to use Youdao translation, speed is very fast, but different translation api translated content is a little different, Which one you choose depends on your preference)
"log": 'CLOSE' does not print logs on the console,'OPEN' prints logs on the console
"embeddings": 'none' is not used. Other: Select the model you want (if there is no model in the embeddingsStrength folder, embeddings and EmbeddingsStrength are not displayed)
"embeddingsStrength": it sets the weight,
Tweak Keywords CN2EN
Display the input content with CLIP Text Encode CN2EN to display the translated content; Due to the limitations of the translation api, there may be some problems with the translated format, you can correct it here if necessary; If you don't think you want to translate certain words, you can edit specific words, which can make your keywords more perfect and produce better pictures If the tweak_keywords_CN2EN node cannot view content after the ComfyUI code is updated, check whether the folder tweak_keywords_CN2EN exists in the ComfyUI\web\extensions path first, If yes, you can decompress tweak_keywords_CN2EN.zip (path: ComfyUI\custom_nodes\comfy_translation_node\ tweak_Keywords_cn2en.zip). Manually add it to ComfyUI\web\extensions (it is not usually overwritten, I give you a zip pack just in case)
